Part 1: Primer
Introduction
Authentication, Authorisation, OAuth, OAuth 2, OIDC… we often find that engineers and development teams experience a lack of understanding and even fear around these concepts. Comments like ‘I just can’t get my head around auth’ and ‘auth just fills me with dread’ are all too common. Engineers often become overwhelmed at the amount of conflicting information available on these subjects and the rate of change that has occurred. With Cyber Security attacks on the rise, it is imperative that technical staff have a good understanding of some of these mechanisms and which are most appropriate to their applications and organisations.
This series aims to break down modern authentication / authorisation practices and how they work, with some concrete examples to help bolster understanding. This article will introduce some of the important concepts around authentication and authorisation in modern applications and how they work in practice. Subsequent articles in this series will implement some of these mechanisms in real world scenarios.
Key terms and concepts
First, let’s introduce some of the important terms and concepts before diving into the details.
Authentication vs Authorisation
Authentication is about proving who a user is while authorisation is about deciding what that user is allowed to do.
OAuth
OAuth (Open Authorisation) is the industry standard protocol for authorisation. As you will see in the remainder of this article, it allows a website or application to access resources hosted by other applications on behalf of a user. It does this by providing a number of ‘flows’ depending on the types of applications involved and leverages Access Tokens in order to control this access. OAuth was designed to address authorisation, not authentication
OAuth vs Oauth2 vs Oauth 2.1
OAuth 1 has been largely superseded by Oauth 2. A detailed comparison of OAuth 2 vs OAuth 1 is beyond the scope of this article. The main point here is, when you see OAuth, think OAuth 2 (which is what the remainder of this series concentrates on)
OAuth 2.1 builds on OAuth 2.0. Default security practices are improved and some areas simplified. There are no fundamental differences between OAuth 2.1 and OAuth 2.0 and you will often see the terms used interchangeably. This article concentrates on 2.1 but calls out where there are changes.
OIDC
OIDC (OpenID Connect) is a protocol that sits on top of OAuth. Whilst OAuth is specifically concerned with authorisation (what a user is allowed to do), OIDC is about authentication (the identity of the user)
JWT
Tokens used in both OAuth and OIDC are generally in the form of a JWT (JSON Web Token). JWT is a compact and self-contained format for representing token information. JWT tokens contain three parts (separated by a ‘.’):
- Header - contains information about the type of token and the signing algorithm used.
- Payload - contains ‘claims’ which are fields of information about an entity (a user in our case)
- Signature - the signature is used to ensure the JWT was created/signed by the correct keypair and has not been tampered with
The 3 parts of the token are base64 encoded. When debugging auth flows it can be useful to copy the Authorisation header in the JWT format of xxxxx.yyyyy.zzzzz and paste it into a JWT decoder such as jwt.io to see the full set of fields / claims.
Authorisation via OAuth
In order to best illustrate OAuth in action, we will introduce a real world scenario:
“A user named Bob would like to use a new calendar creation application called bookit.com and Bob wants to allow it to access his photographs stored on Google Drive.”
We’ll start by looking at the Actors involved in a typical OAuth flow, discuss scopes, client types, choose a flow that best suits this use case, and provide a walkthrough. We’ll outline some of the important endpoints from the OAuth specification, take a deeper dive into some parts of the flow and why they are so important.
Actors
Below is a list of actors introduced by the OAuth specification and how they align in this scenario:
- Resource Owner - The entity that can grant access to the protected resources. This is usually the end user (Bob in this case)
- Client - The application requesting access to the protected resource on behalf of the resource owner. (The bookit.com application)
- Resource Server - The server hosting the protected resources. (Google Drive)
- Authorisation Server - The server that authenticates the Resource Owner and provides authorisation via Access Tokens. (Google Authorisation Server)
The diagram below shows the actors in this scenario and the roles they play:

Scopes
Scopes in OAuth are like permissions. They are the list of things that the user is going to agree to allow the application to do on behalf of them. In our example, the scope is ‘photos.read’, meaning that Bob wants to agree for bookit.com to access his photos on Google Drive. These scope strings are declared and managed by the Authorisation Server. The scopes available in a given Authorisation Server can be advertised via some of the discovery endpoints that are often made available, depending on the Authorisation Server being used.
Flows / Grant types
As we alluded to earlier, the OAuth protocol specifies a number of flows or ‘grant types’ which can be used to satisfy the requirement as outlined in the bookit example above. OAuth 2.1 has consolidated this list of Grant Types and the type to choose depends on the specific use case and the types of applications involved. The main Grant Types are as follows
- Authorisation Code - the recommended Grant Type when possible. This is a 2 step process that involves a user and browser redirects to provide a secure flow for generating an access token. The remainder of this series will focus on this Grant Type.
- Client Credentials - Used for machine to machine communication where there is no user involved. Think of a scheduled job that needs to access resources on a resource server somewhere.
- Refresh - A mechanism for exchanging a refresh token for a new access token but without the user needing to go through the authentication and authorisation steps again. Note that Refresh tokens can be revoked in the Authorisation Server (unlike access tokens, which will always be valid until they expire) to prevent subsequent access tokens being granted via that refresh token.
There are some extension Grant Types available which are beyond the scope of this article. It is also worth noting that a number of Grant Types that were available in OAuth 2.0 have been deprecated in OAuth 2.1.
- Implicit - previously intended for applications running in a browser without a backend
- Password - a way to exchange explicit security credentials for an access token. Previously used for native clients
Our use case above has all the components that lend itself best to one of the most widely used and secure Grant Types called ‘Authorisation Code’.
Let's take a look at the exact steps involved in this particular Authorisation Code Grant flow. Note that Bob will be accessing bookit.com in a browser, this is important as the Authorisation Grant flow depends on browser redirects to complete successfully:
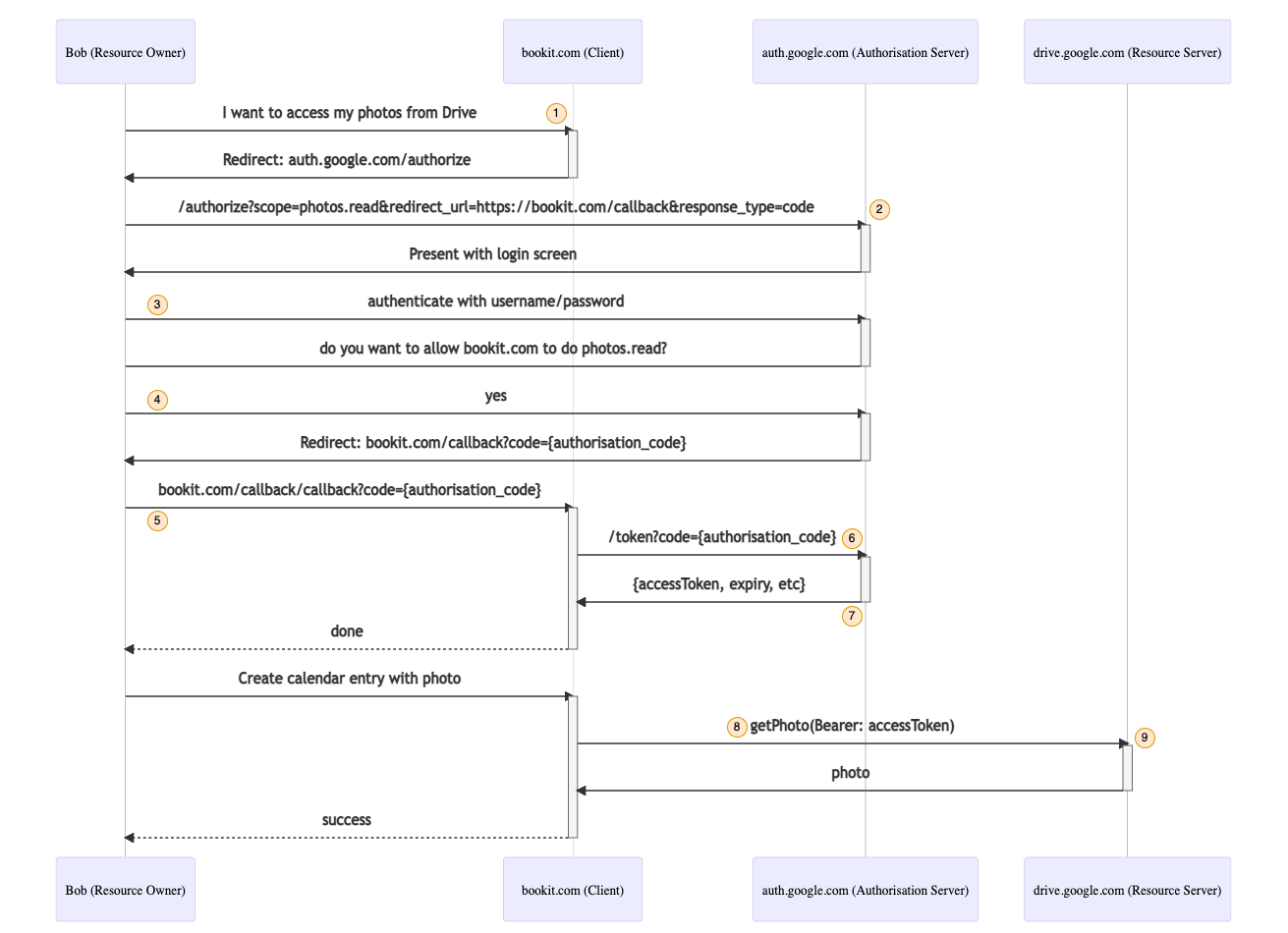
- Bob would like to allow bookit.com to access his Drive photographs.
- Bookit.com returns a HTTP redirect response to Bob’s Browser sending him to auth.google.com to perform the authorise step. The query parameters on the redirect URL include:
- scope=photos.read - what we want to allow bookit.com to be allowed to do
- response_type=code - indicating we want the authorisation code grant type
- redirect_url - the URL to redirect the user to once the authorisation step is successful
- Bob’s browser displays a login form returned by auth.google.com and Bob is asked to authenticate with Google Auth Server, using his Google username and password.
- Upon Successful authentication, Google Auth Server asks Bob to confirm he is happy to grant the application bookit.com ‘photos.read’ access. Bob confirms he is happy with this.
- Bob’s Browser is now redirected back to the bookit.com callback endpoint, passing a query param called ‘code’ which is the Authorisation Code that has been created
- Bookit.com now needs to exchange the authorisation code for an actual access token. Bookit.com calls the Authorisation Server’s /token endpoint with the authorisation code to do this.
- The Authorisation Server responds with a successful response that includes an access token and an expiry time. The access token is in the form of a JWT, issued and signed by the Google Authorisation Server and includes a scope claim of ‘photos.read’.
- Bob can now ask bookit.com to retrieve photos from Google Drive until the access token expires. Each time bookit.com does that, it will include the access token as a bearer token in a HTTP Authorisation header
- Each time Google Drive receives a call from bookit.com it can verify the access token before responding. Typically it will perform validation such as:
- Ensuring the token is issued and signed by the correct Authorisation Server (auth.google.com)
- Ensure that the token has the required scope (photos.read in this case)
- Ensure the token has not expired
OAuth endpoints
The OAuth specification defines 2 main endpoints as you can see from the 2 calls to the Google Authorisation Server in the flow above (Steps 2 and 6 in the sequence diagram above):
- /authorize - This endpoint is concerned with the authorisation itself. I.e. obtaining authorisation that the user has allowed consent to the application for that scope. The eventually resulting response type depends on the grant type, for the Authorisation Code Grant Type, the response will include an authorisation code.
- /token - This endpoint is for exchanging an authorisation grant for an access token. In our example, the authorisation step returned an authorisation code, and the application then exchanged it for an access token. The response can also contain a refresh token that can be used to exchange for another access token once the previous one has expired, without the user having to go through the authorisation step again.
Confidential vs Public clients
There is another consideration when using OAuth flows. Whether the client will be ‘Confidential’ or ‘Public’. Confidential clients can be used when the component calling /token to exchange the Authorisation Code for an access token is able to store secrets securely to include as part of the call. An example of a Confidential Client is a traditional server side web application where HTML is rendered server-side. Secrets can be stored here and not be available to any user and the call to /token can happen in a private manner and is not viewable by the user.
Public clients involve a component where secrets can’t be securely stored and the call to /token typically happens from the browser, meaning that a user can have full visibility of the call. An example of this type of application is a Single Page Application (SPA) such as a React application; this cannot store secrets because they would be available to the user in a browser.
More detail on the OAuth calls
In the walkthrough above, to aid clarity, we glossed over a number of security details that are crucial to OAuth, but they need to be explained in more detail to understand the security behind OAuth.
- PKCE The 2 API calls to the Authorisation Server should actually involve some more parameters than shown above. In order to prevent Code Injection and CSRF attacks, a mechanism called PKCE (Proof Key for Code Exchange) - pronounced Pixie is used. This was an optional addition to the Authorisation Grant type in OAuth 2.0 (which used a state parameter to prevent these attacks) but is mandatory in OAuth 2.1. The second article in this series shows this in more detail but for now it is enough to know that the purpose of PKCE is to ensure that a malicious user cannot intercept an authorisation code and exchange it themselves for a token.
- Client Secret In ‘Confidential Clients’ the call to the /token endpoint in step 6 will also typically contain a client_secret - this is a secret string which is associated with the client when it is initially registered with the Authorisation Server during initial setup. Initial setup is a one off activity that happens before an application can use OAuth. The client (bookit.com) must be registered with the Authorisation Server, at which point the client will be issued with a client ID and secret. Note that setup is not part of the OAuth spec, so each Authorisation Server will have a slightly different implementation for this.
- The client_secret is a sensitive value and if used, is one of the reasons that this /token call needs to be made on a ‘back channel’ i.e. not from a browser that is accessible to a human user; this is why it is only appropriate for a Confidential client. In ‘Public’ clients, a client_secret would not be used, in this case PKCE should always be used.
- Token Verification When a Resource Server verifies a token (step 9), it can do some of it based on the contents of a token, e.g. ensuring the expiry time has not passed and that the token contains the correct scope to perform the action. But how does the Resource Server know that it can trust a token? What stops Bob modifying his JWT token and using that instead? This is thanks to the signature of the JWT. Using asymmetric encryption techniques, the Resource Server can assert that 1) the token has been created by the correct Authorisation Server and 2) that it has not been tampered with. OAuth Authorisation Servers typically provide a list of public keys from key pairs that it uses to sign tokens. The Resource Server can obtain the public key for the key pair that was used to sign the token and use it to verify the signature. This is secure because that signature could only have been created by the holder of the private key of that pair, which only the Authorisation Server will have.
- Redirect URL verification Whenever a redirect URL is provided (e.g. on both Authorisation Server API calls), the RedirectURLs must be validated against the list of acceptable URLs provided when the application is registered at setup time. I.e. callers can’t just ask the Authorisation Server to redirect to any arbitrary URL.
Authentication via OIDC
Hopefully it is now clear that OAuth is about authorisation and not authentication. It has no support for identity or ‘who someone is’, it is only concerned with ‘what someone can do’. This is where OpenID comes in.
OpenID Connect extends OAuth by introducing:
- A new id_token
- A new UserInfo endpoint
- New standard scopes and claims for identities such as profile, email, address and phone
Discovery endpoints
To look at some of this in action, lets see a typical authorisation request using OIDC (notice the scopes of openid, profile and email)
https://authorization-server.com/authorize?
response_type=code
&client_id=zYxTG8yyNtuPvm3et--kDVDC
&redirect_uri=https://www.oauth.com/playground/oidc.html
&scope=openid+profile+email+photos
&state=P6A0oPurupqWg43d
&nonce=12Pk2dUpTv6SqRuV
And the response that comes back from the /token endpoint (notice the new id_token) field
{
"token_type": "Bearer",
"expires_in": 86400,
"access_token": "Gf…_IP",
"scope": "openid profile email photo",
"id_token": "eyJraWQ….Q"
}
Because the id_token is a JWT, it can be decoded using jwt.io and this time the claims in the body will include identity related fields such as name and email.
{
"sub": "precious-centipede@example.com",
"name": "Precious Centipede",
"email": "precious-centipede@example.com",
"iss": "https://pk-demo.okta.com/oauth2/default",
"aud": "zYxTG8yyNtuPvm3et--kDVDC",
"iat": 1683291571,
"exp": 1685883571,
"amr": [
"pwd"
]
}
Summary and further reading
This article has introduced some key concepts around authentication and authorisation and looked at what is provided by the OAuth and OIDC protocols. The next couple of articles in this series will pick an Authorisation Server and show how you might use it to secure your services depending on the types of applications you have.
- Part 2 shows a concrete example of how OAuth and OIDC can be used in a Public application to complement each other, providing a good solution for authentication and authorisation for a range of use cases.
- Part 3 does something similar, but this time demonstrates a confidential client in action.
- Part 4 Looks at using a custom Authorisation Server to replace Keycloak, chosen for Part 2 and 3.
There are many OAuth and OIDC references online and we’d encourage you to research further. The following is a great video by OKTA to introduce some of these ideas: Oauth 2.0 and OpenID connect in plain english
Finally, a brilliant resource to help learn some of the OAuth / OIDC flows is the OAuth playground where you can follow each of the flows step by step.




