Kafka Consume & Produce: Spring Boot Demo
Rob Golder - July 2022
Rob Golder - July 2022
Introduction
The Kafka Consumer and Producer APIs provide the ability to read and write data from topics in the Kafka cluster. These APIs form the foundation of the Kafka API ecosystem with the Kafka Connect API and Kafka Streams API building on these APIs under their hoods. This article provides an overview of a Spring Boot application that demonstrates consuming and producing messages using the Spring Kafka API abstraction over these Consumer and Producer APIs.
The source code for the application is available here:
https://github.com/lydtechconsulting/kafka-springboot-consume-produce/tree/v1.0.0
Application Overview
The application consumes messages from an inbound topic and writes resulting messages to an outbound topic.
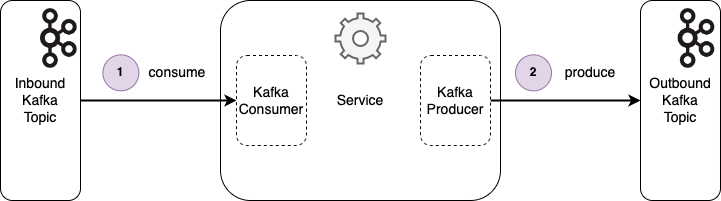
Figure 1: Application with Consumer and Producer
The application is intentionally simple in order to focus on the core consume and produce, and provide a starting point for developing a Spring Boot application that uses Kafka as the messaging broker. Concerns such as message deduplication, idempotency, ordering and transactions are not covered here, but see the 'More On Kafka' section below for articles covering these and other related areas.
Consuming Messages
Kafka Listener
The starting point for consuming messages from the Kafka broker is to define a consumer with a listen method annotated with the spring-kafka @KafkaListener annotation. This can be seen in the demo application KafkaDemoConsumer class:
@KafkaListener(topics = "demo-inbound-topic",
groupId = "demo-consumer-group",
containerFactory = "kafkaListenerContainerFactory")
public void listen(@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) String key,
@Payload final String payload) {
...
}The annotation takes a number of configuration parameters. In this case it is configured to consume messages from the demo-inbound-topic topic, as part of the consumer group named demo-consumer-group. It also specifies the container factory to use, kafkaListenerContainerFactory.
The consumer class itself is annotated with the Spring framework @Component annotation so that it is instantiated and managed by the Spring container.
Consumer Group
The importance of the consumer group is that any other instances of the consumer that have the same consumer group name and are listening to the same topic will have the topic partitions assigned between them. Each partition is only assigned to one consumer instance within the consumer group. This means that throughput can be scaled up by increasing the number of topic partitions and the number of consumer instances listening within a group.
If a consumer instance belonging to a different consumer group is listening to the same topic, that will receive the same messages as our consumer. This would be a typical scenario when a different application is also interested in receiving and processing the same messages.
Listener Container Factory
The listener container factory is responsible for receiving messages from the broker and invoking the listener method with the messages. The value of the
@KafkaListener annotation containerFactory property is the Spring bean name to use as the factory. This is specified in the Spring Boot application configuration class KafkaDemoConfiguration:
@Bean
public ConcurrentKafkaListenerContainerFactory kafkaListenerContainerFactory(final ConsumerFactory consumerFactory) {
final ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory();
factory.setConsumerFactory(consumerFactory);
return factory;
} The container factory is highly configurable, including concerns such as concurrency, retry, message filtering, error handling and more, that will affect the behaviour of the listeners it is responsible for. Some of these concerns can also be configured on the @KafkaListener annotation on the consumer.
Consumer Factory
The listener container factory is provided with the consumer configuration properties via the ConsumerFactory bean. This bean is also declared in the KafkaDemoConfiguration class:
@Bean
public ConsumerFactory consumerFactory(@Value("${kafka.bootstrap-servers}") final String bootstrapServers) {
final Map config = new HashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
config.put(ConsumerConfig.GROUP_ID_CONFIG, "demo-consumer-group-2");
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(config);
} This provides the ability to fully configure the consumer itself, from the location of the Kafka broker servers, to the message serialiser/deserialiser to use, configuring timeouts, batch size and much more. Note that any overlapping configuration defined on the @KafkaListener annotation takes precedence over this consumer factory configuration. For example, the consumer group Id can be specified on both. In this case, the consumer would be part of the consumer group demo-consumer-group.
The full configuration options can be viewed in the Apache Kafka consumer configuration documentation here:
https://kafka.apache.org/documentation/#consumerconfigs
Producing Messages
KafkaTemplate
The spring-kafka library provides a KafkaTemplate bean that is used for producing messages to Kafka. It provides an abstraction over the low level Apache Kafka Producer API making the job for the developer to send messages straightforward.
The KafkaTemplate bean is configured in the KafkaDemoConfiguration class:
@Bean
public KafkaTemplate kafkaTemplate(final ProducerFactory producerFactory) {
return new KafkaTemplate<>(producerFactory);
} KafkaTemplate has a number of overloaded send(..) methods. In the demo application the send(..) takes a ProducerRecord which is an Apache Kafka client library class. It is called from an application utility class KafkaClient:
final ProducerRecord record = new ProducerRecord<>(properties.getOutboundTopic(), key, payload);
final SendResult result = (SendResult) kafkaTemplate.send(record).get();
final RecordMetadata metadata = result.getRecordMetadata(); The send(..) is asynchronous, returning a ListenableFuture. To block until the send has completed, get() is called on the ListenableFuture that is returned. The SendResult response contains the metadata for the record that has been acknowledged by the broker, with information such as the partition and topic the record was written to, and its timestamp.
Producer Factory
The KafkaTemplate bean is passed the necessary configuration via the ProducerFactory, which is also defined in the KafkaDemoConfiguration class:
@Bean
public ProducerFactory producerFactory(@Value("${kafka.bootstrap-servers}") final String bootstrapServers) {
final Map config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(config);
} In the demo application only the serialiser classes for marshalling the key and payload, and the location of the Kafka broker bootstrap servers are configured. As with the consumer configuration, all aspect of the produce can be configured, from retries, to batch size, to idempotency, to transactional behaviour.
The full configuration options can be viewed in the Apache Kafka producer configuration documentation here:
https://kafka.apache.org/documentation/#producerconfigs
Testing
Testing the Kafka consume and produce functionality within the application is of course a key part of its development. There are different tools and frameworks that can be used to facilitate this, across unit, integration and component testing. These are demonstrated in this application code base, and covered in detail in the Kafka Consume & Produce: Testing article.
Conclusion
Utilising the Kafka Consumer and Producer APIs provide the starting point for building an application that uses Kafka as its messaging broker. The Spring Kafka module provides an abstraction over the low level APIs providing a low learning curve in its adoption. It makes it straightforward to configure all aspects of the consume and produce. It also facilitates the ability to write good quality tests on the consume and produce application concerns.
Source Code
The source code for the accompanying Spring Boot demo application is available here:
https://github.com/lydtechconsulting/kafka-springboot-consume-produce/tree/v1.0.0
More On Kafka
The following accompanying articles cover the Consume & Produce flow:
Kafka Consume & Produce: Testing: covers the tools and frameworks available to comprehensively test a Spring Boot application using Kafka as the messaging broker.
Kafka Consume & Produce: At-Least-Once Delivery: looks at the default at-least-once messaging guarantees provided by Kafka.
The following articles delve into different aspects of Kafka, with each building on the foundation of the Consumer and Producer APIs:
The Idempotent Consumer & Transactional Outbox: using the Idempotent Consumer pattern along with the transactional outbox to deduplicate messages.
The Consumer Retry: the options and trade-offs to consider when choosing between stateless and stateful retry approaches.
The Idempotent Producer: configuring the Producer to be idempotent to stop duplicate writes.
The Producer Acks: understanding the different options for the Producer acknowledgement configuration, and their impacts and trade-offs.
The Producer Message Batching: sending messages in batches by the Producer, trading off throughput and latency.
The Deduplication Patterns: patterns that can be applied to deduplicate messages.
The Kafka Transactions: achieving exactly-once messaging semantics with Kafka Transactions.
View this article on our Medium Publication.

