Introduction
Batching messages enables a Kafka producer to increase its throughput. Reducing the number of network requests the producer makes in order to send data will improve the performance of the system. The cost of increased throughput is increased latency. Understanding the application’s data characteristics is key to ensuring that message batching can be optimised, and the right balance between throughput and latency is achieved.
Message Throughput
Optimising throughput is the action of maximising the amount of data being sent between producers and consumers within a given period of time. There are multiple ways that an application’s throughput can be increased when using Kafka as the messaging broker, including altering topic partition counts, message compression, memory allocation and producer acks (the latter is covered here: Producer Acks)
One option is to batch together messages that are being published to a topic partition into a single request, and this is the focus of this article. Sending the same amount of data in fewer requests (with larger batch sizes) improves the performance on both the client and the server. There is less load on the producers and less CPU overhead required to process the smaller number of requests.
In order to batch messages together the producer must wait a configurable period of time while it receives messages to send. This wait time is latency, so the increased throughput comes at the cost of increased latency.
Messages are read in batches by the consumer as it polls the topic partition. This is another important factor in tuning the overall throughput of the system. The configuration and tuning for the consumer side is out of scope for this article.
Producer Batch Configuration
There are two parameters to configure on the Kafka producer that control message batching, and understanding these is key to optimising throughput. These are batch.size and linger.ms.
ParameterUsageDefaultbatch.sizeThe upper bound batch size in bytes16384 byteslinger.msThe maximum amount of time to wait for the batch.size to be reached before sending the batch0 milliseconds
Note that the batch.size is in fact a threshold which once met or exceeded will trigger the sending of the batch request.
Configuring a larger batch.size will (usually) result in fewer requests being sent. The producer will await up to the number of milliseconds defined in the linger.ms configuration to collate messages for the topic partition until the batch.size is reached. At this point the batch of messages will be sent.
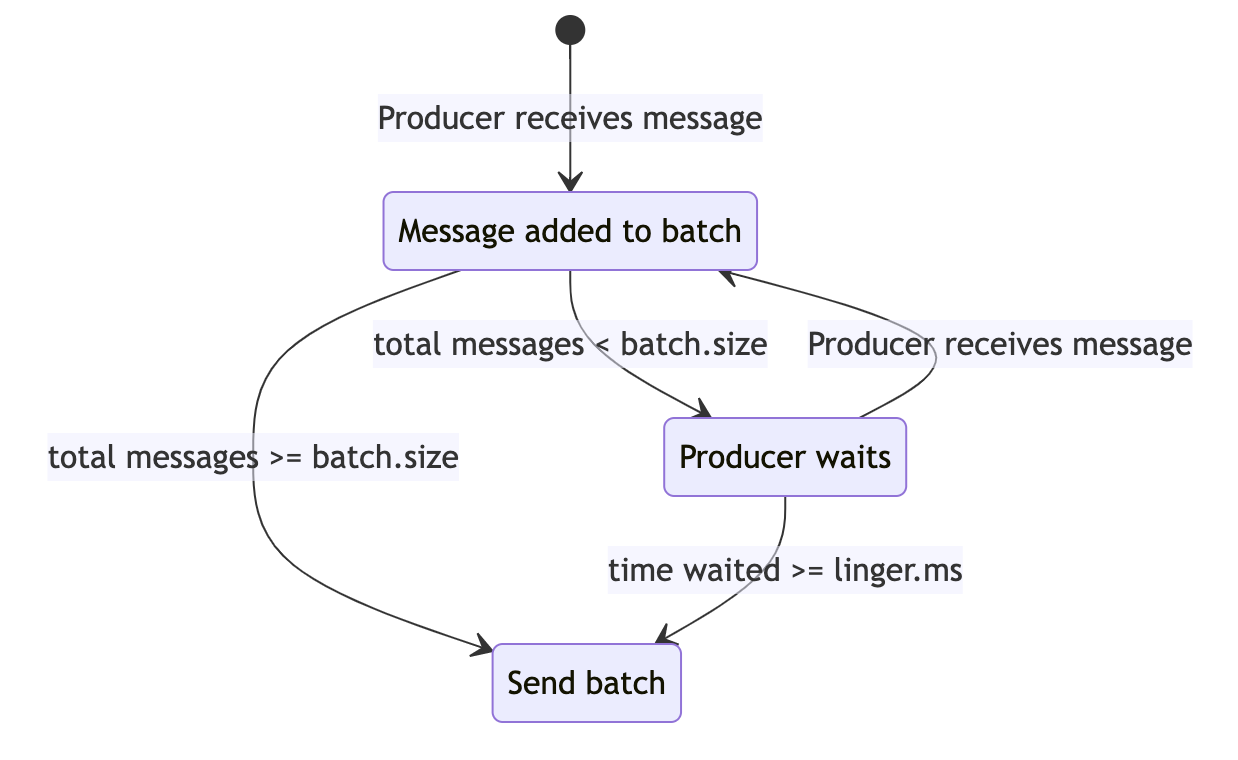
The caveat is that if the application is producing a lower volume of data then the batch.size may not be reached within the linger.ms timeframe. If the batch.size is not being reached within the configured window then the upshot is that latency is being introduced, as the producer delays before sending each request. The producer could just be attempting to publish one message within this window, in which case the batch size will just be one. In such a scenario, with a linger.ms of 5 milliseconds, then this has introduced a latency of 5 milliseconds for this and any similar send.
Tuning Configuration
In order to determine the optimal values for batch.size and linger.ms a number of factors need to be considered. First of all, the volume of messages being produced and the actual typical sizes of messages are key to understand. Other factors including the number of partitions in the topic, and whether messages include a message key, will also impact the calculation. If a producer is sending messages in a round robin to different partitions then these will be batched in separate requests, so contributing more slowly to reaching the request batch.size.
If a message key is being used, which enforces the write of messages to the same partition, and there are likely to be many such messages being produced within the linger.ms window, then these would be batched together. For messages with a null key, a Sticky Partitioner strategy can be utilised to ensure these messages are batched together and sent to a single partition. The next batch for null keyed messages can then be sent to another partition to ensure load is still evenly distributed, but the batching is still being optimised.
If message compression is being used on the producer, this will of course affect the time to reach the batch.size limit, as message sizes are smaller.
As well as the risk of introducing latency by configuring a larger batch.size while the batch is being filled, more memory needs to be allocated to the message to cater for the additional messages. On the flip side a small batch size, or small window allowed by the linger.ms setting, can reduce throughput as the number of requests for the messages being produced increases. Indeed a linger.ms set to 0 all but disables batching, although some batching can still occur due to the time it takes for the request to be created and sent by the producer. As the documentation on the org.apache.kafka.clients.producer.KafkaProducer states:
Note that records that arrive close together in time will generally batch together even with linger.ms=0 so under heavy load batching will occur regardless of the linger configuration;
Benchmark Testing
In order to determine the optimum values for the batch configuration parameters, one approach would be to utilise a microbenchmarking library such as JMH. This article describes the library and its usage: Microbenchmarking with JMH
For the purposes of this tuning exercise, a dockerised Kafka broker would be spun up, and the tests run using the application to produce messages with different batch.size and linger.ms configurations. The tests should be sending messages of the expected size and with the expected load to reflect the Production system. This should provide a good framework of how these parameters should be configured to achieve the highest throughput whilst minimising latency.
Conclusion
Using message batching in the Kafka producer is an important tool to optimise throughput. However the cost of higher throughput is higher latency, so a good understanding of the data volumes and message sizes is required in order to correctly configure the parameters on the producer responsible for batching.




