Introduction
Kafka Streams stateful processing enables the grouping of related events that arrive at different times by capturing and storing them. Operations can then be performed on them such as joins, reduce, counts and aggregations. The results can be materialised into tables which are queryable. Kafka Streams are backed by a persistent or in-memory state store, themselves being backed by Kafka changelog topics, providing full fault tolerance.
The accompanying Kafka Streams Spring Boot application source code is available here.
This is one of a series of articles covering different aspects of Kafka Streams. Jump to the 'More On Kafka Streams...' section below to explore.
RocksDB
Kafka Streams uses RocksDB as the default state store. It is an embedded state store meaning writes do not entail a network call. This removes latency, ensures it does not become a bottleneck in the stream processing, and means this is not a potential failure point that would need to be catered for. It is a key/value store, with records persisted as their byte representation resulting in fast reads and writes. It is a persistent rather than in-memory state store with writes being flushed to disk asynchronously.
Changelog Topics
With RocksDB asynchronously flushing writes to disk there is therefore a small window where records written to the store are in-memory before the flush occurs. However in a failure scenario these records are not lost.
State stores are backed by Kafka changelog topics by default, capturing state for every key in the store. These are internal Kafka topics, and they benefit from all of Kafka’s architected resilience with topic replication and failover.
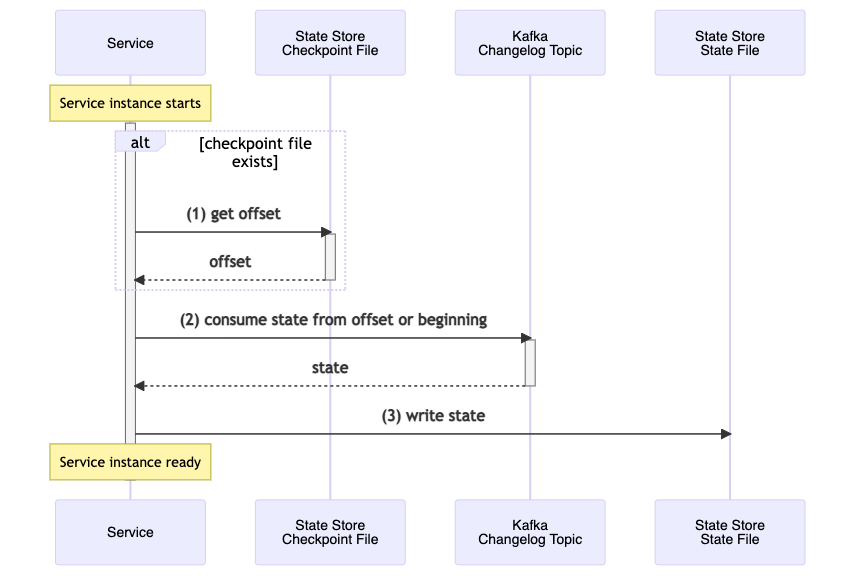
The following applies to non-transactional processing. Transactional processing will be covered in an upcoming article. When state has to be restored the Kafka Streams application first checks for the presence of a state store file, the checkpoint file, which tracks the last known offset that the application has captured the state for. If the file is present the application retrieves this offset and uses a dedicated changelog consumer to replay the records from the changelog topic from that offset. These records contain the state that was in-memory at the point of failure. If the checkpoint file is not present then the application replays all the events from the changelog topic. Upon completion the full application state has been restored.

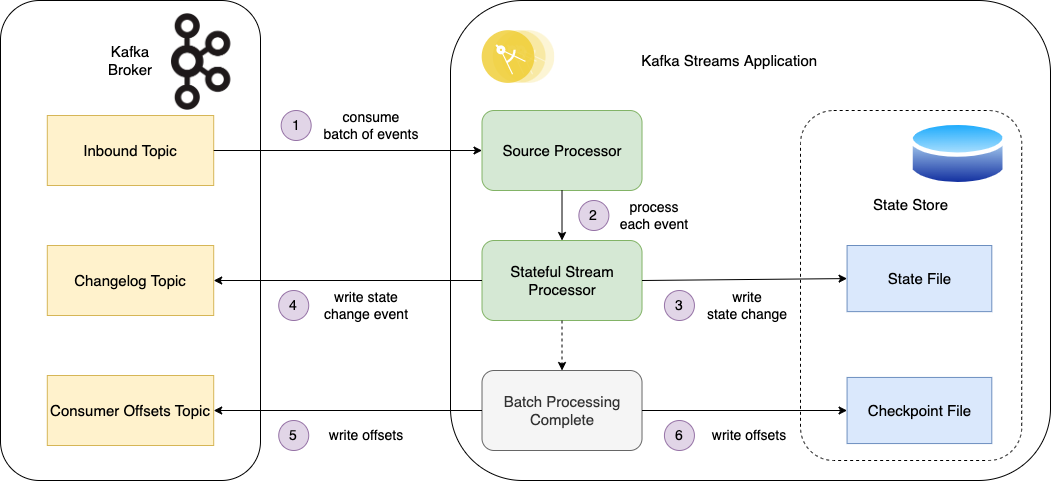
Once the service has restored any state following start up it is ready to stream and process new events. The source processor consumes a batch of events from the inbound topic and passes each through its processor topology. The stateful processor writes the change to the state store (a RocksDB file) then writes the state change to the backing changelog topic. It writes the consumer offsets to mark the batch processing as complete, before writing the offsets to the checkpoint file. This then enables the service to recover on failure.
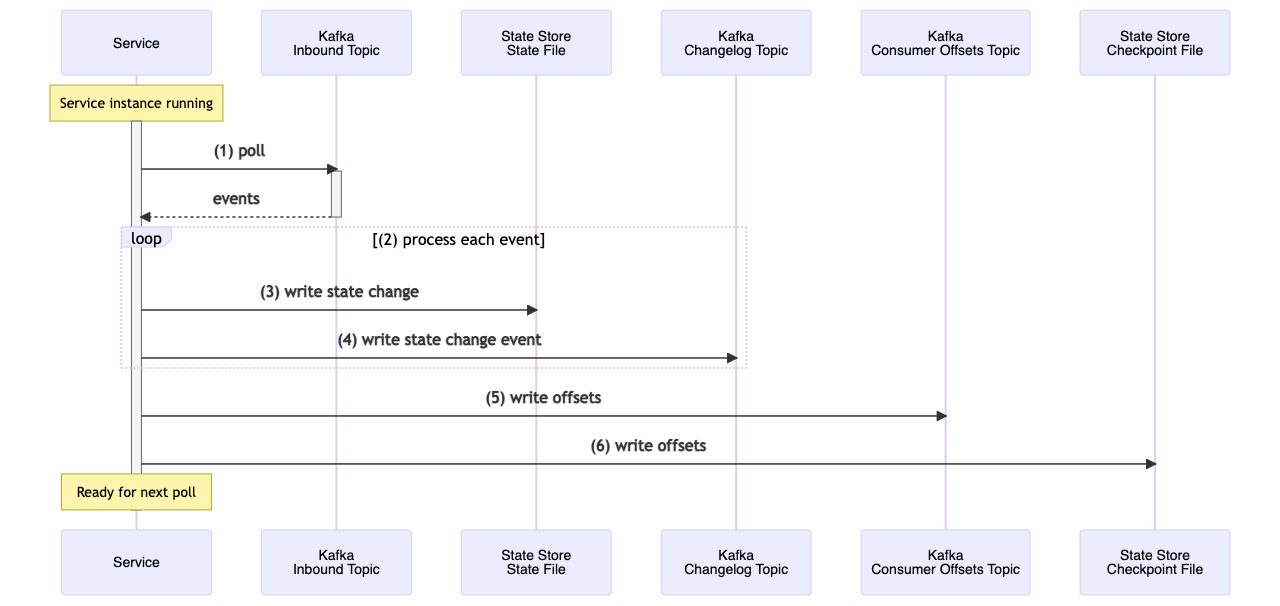
Changelog topics are compacted by default. This means that only the latest value for a given key is retained. This means that on recovery less events need to be consumed to rebuild state, making the process more efficient. Other mechanisms that can be employed to keep changelog topics as small as possible include using tombstones to mark records for a given key as deleted, and using a windowed store with a low retention period for records.
Standby Replicas
A Kafka Streams application can be configured to use one or more standby replicas, via the config parameter num.standby.replicas. These are complete copies of local state held by another application instance. If the first application instance fails, the failed task is assigned to the instance with the standby replica. This can greatly reduce the recovery time as the majority of the state will already be built.
Consumer Group Rebalance
When a new consumer instance joins or leaves a consumer group, whether through expected scaling of the application or due to failure scenarios, a consumer group is rebalanced. Typically topic partition assignments are revoked and reassigned to the consumers that now comprise the consumer group. This results in 'stop-the-world' processing, as no events are consumed while this operation is underway. Once the rebalance is complete, consumers have to rebuild their local state from the state store and changelog topics. This can be a costly operation as further event processing is paused until this has completed.
To counter this, Kafka Streams uses by default a StreamsPartitionAssignor which uses a StickyPartitionAssignor. When a consumer rebalance is triggered, existing consumers attempt to hold on to their partition assignments through 'incremental rebalance'. Only those partitions that need to be reassigned will therefore require their associated state to be rebuilt. This mechanism greatly reduces the impact that consumer group rebalances would otherwise have.
One option to stop unnecessary rebalances occurring is to configure static group membership. This means that if a consumer with a static group.instance.id stops and restarts within a configured period that group membership remains unchanged, so a rebalance is not triggered. An example would be during a rolling upgrade where an application pod is bounced.
With standby replicas configured, if a consumer is rebalancing and rebuilding its state store it is possible to redirect queries to the instance with the standby replica in order to return the requested data.
Consumer group rebalance, including incremental rebalance and static group membership, is covered in detail in the Kafka Consumer Group Rebalance article.
State Store Trade-Offs
While RocksDB is the default state store, any state store can be plugged in in its place. The decision on which state store to use will be driven by the use cases for the streams application. There are a number of trade offs to consider based on this technology choice. For example one state store may favour high throughput, another fast recovery, and another resilience. An in-memory state store could be used for fastest performance. It is less complex operationally than a persistent store as it does not require consideration for factors around disk resilience and read/write tuning. However if the application stops and restarts with an in-memory store, the recovery would be a lot longer as the full state must be replayed and rebuilt from the changelog topics each time.
Stateful Processing Example
The accompanying Spring Boot application demonstrates stateful processing using a KTable to materialise account balances for payment events being processed. This is covered in detail in the Kafka Streams: Spring Boot Demo article.
Conclusion
Related events can be stored, operated on, and enriched as part of the stream processing. The state store provides the basis of stateful processing using Kafka Streams, with the results being materialised into a view that can be queried. Backed by changelog topics the state store benefits from the resilience and fault tolerance that Kafka’s architecture provides.
Source Code
The source code for the accompanying Kafka Streams application is available here:
https://github.com/lydtechconsulting/kafka-streams/tree/v1.3.0
More On Kafka Streams...
- The Kafka Streams: Introduction article delves into the API and covers its benefits and characteristics.
- The Kafka Streams: Spring Boot Demo article details the application that is under test.
- The Kafka Streams: Testing article examines the options and tools available to comprehensively test a Kafka Streams application.
- The Kafka Streams: Transactions & Exactly-Once Messaging article detailing how to achieve exactly-once messaging using Kafka Transactions with a Kafka Streams application.
Resources
- Mastering Kafka Streams and ksqlDB: Building real-time data systems by Example by Mitch Seymour
- Kafka - The Definitive Guide: Real-Time Data and Stream Processing at Scale by Gwen Shapira, Todd Palino, Rajini Sivaram




