Kafka Streams: Introduction
Rob Golder - May 2022
Rob Golder - May 2022
Introduction
Kafka Streams provides an API for message streaming that incorporates a framework for processing, enriching, and transforming messages. It is a fully scalable, reliable, and maintainable library enabling fast processing of unbounded datasets in real-time with low latency. This article provides an introduction to the API, exploring its main characteristics and benefits.
This is one of a series of articles covering different aspects of Kafka Streams, including an article on the accompanying Kafka Streams Spring Boot application that illustrates how to use the API. Jump to the 'More On Kafka Streams...' section below to explore.
The Kafka API Ecosystem
The Kafka Streams API is a client-side library that sits alongside the existing APIs, namely the Consumer, Producer, and Connect APIs. The Consumer and Producer APIs read and write to Kafka topics. The Kafka Connect API is used for connecting to external datastores such as databases to read or write data to topics. Kafka Streams, which use the Consumer and Producer APIs under the hood, provides the ability to stream messages in real-time from a topic, processing and reacting to the data, before writing the transformed and enriched data to other topics.

Figure 1: Kafka Streams Application
Processor Topology
Kafka Streams uses the concept of ‘Processor Topology’, which refers to the collection of processors that make up the data flow of any one stream. There are three processor types, namely source, stream and sink. A source processor is responsible for consuming data from source topics. The data is handed off to one or more stream or sink processors. Stream processors are responsible for enrichment, filtering and transformation of the data. There is typically a chain of stream processors as the data flows through a number of steps, before optionally being passed to one or more sink processors. Sink processors are responsible for writing the data back to Kafka.
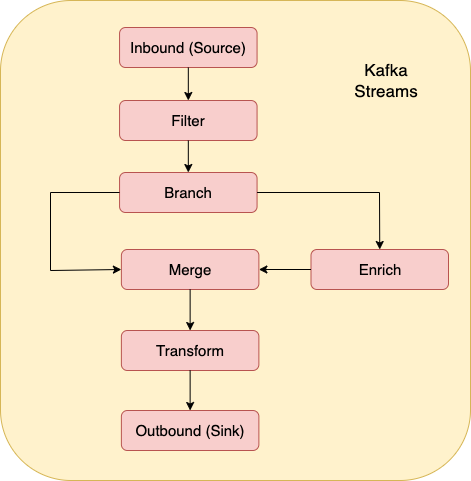
Figure 2: Example stateless topology
Stateful processors then add in the ability to join data from other streams or tables, group data in time windows, and aggregate related events, using a backing store to maintain state.
Each message is passed through a processor topology serially, such that each subsequent message is not processed until the previous one has completed. This depth-first processing strategy ensures low latency. The topology can be divided into sub-topologies, and these sub-topologies will process messages in parallel with other sub-topologies.
Tasks & Threads
Kafka Streams assigns each source topic partition to a task, and each task has its own copy of the topology. A topic with 10 partitions will have 10 tasks. Threads, which are isolated and thread-safe, then execute the tasks. The creation of threads is managed by Kafka Streams so is not a developer concern. The number of threads is configurable, based on the num.streams.threads setting. This cannot exceed the task count. If num.streams.threads was configured to be 5 threads, then with 10 partitions each thread would execute 2 tasks. The higher the thread count the better the utilisation that can be made of the available CPU resources.
Streams & Tables
Data in the topology can be modelled two ways. Either by tracking the whole history of the messages for an entity, or as the latest state of an entity. Streams are used to track the entity history, in other words every event that was applied to an entity. This would be equivalent to the individual insert and subsequent update writes that occur when using a database. Events are processed independently of one another, so Streams processing is therefore stateless.
Tables meanwhile track the current state of the entity only, and are not concerned with the events that were applied during its lifetime. Tables are materialized on the client side into a stateful key-value store. Kafka uses RocksDB by default for this.
Streams DSL vs Processor API
The Kafka Streams DSL provides a higher level and simpler functional API for a developer to use in their Kafka Streams application. It uses a functional programming style (map, join, filter etc) with a fluent API, and incorporates the streams and tables abstractions. Streams are represented by the KStream abstraction. Partitioned tables are represented by the KTable abstraction. They contain a subset of the complete data, being sharded according to the input partitions. An unpartitioned table contains a complete copy of the underlying data and is represented by the GlobalKTable abstraction.
The Streams DSL is built on top of the Processor API, and the developer has the option to interact directly with this API if required. The Processor API gives greater control with lower level granular access to the data, ranging from factors such as access to record metadata to control of operations.
Non-Functional Characteristics
Scalability
Kafka Streams benefits from the scalability that Kafka provides. The unit of work is the individual source topic partition, and the work is distributed across the consumer instances. So scaling is achieved first by increasing the number of partitions in a source topic. As Kafka Streams use Kafka consumers to ingest the data, the number of consumer instances in the consumer group are then scaled up to consume from the partitions.
For example, in the following scenario streaming from a topic scaled to have four partitions, the consumer group has four consumer instances split across two service instances.
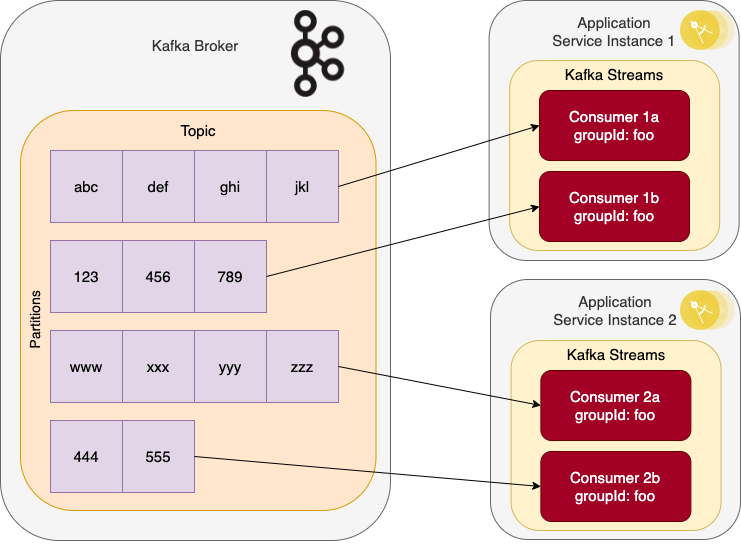
Figure 3: Scaling Kafka Streams
Reliability
As with scalability, Kafka Streams also benefits from the reliability that Kafka provides. Data is replicated across broker instances, so is fault tolerant. If a consumer fails then the partitions it is listening to are reassigned to other consumer instances in the consumer group ensuring no data loss. If a broker node fails then automatic failover again ensures the risk of data loss is minimised.
Maintainability
The Kafka Streams API has been built as a simple, intuitive Java library. There is a low learning curve to using the library from the developer’s perspective, both from developing with the library and from the ease of understanding the streaming concepts it uses. It is a battle hardened library that is reasonably straightforward to troubleshoot issues using standard practices.
Conclusion
The Kafka Streams API adds a powerful streaming layer to the Kafka ecosystem. It provides a straightforward and intuitive API for processing messages, inheriting the non-functional benefits that Kafka provides including scalability and fault tolerance.
More On Kafka Streams...
The Kafka Streams: Spring Boot Demo article covers the accompanying Kafka Streams Spring Boot application, demonstrating stateless and stateful streams processing.
The Kafka Streams: Testing article covers the tools and approaches available to comprehensively test a Kafka Streams application.
The Kafka Streams: State Store article looks at the role and usage of the state store in a stateful Kafka Streams application.
The Kafka Streams: Transactions & Exactly-Once Messaging article detailing how to achieve exactly-once messaging using Kafka Transactions with a Kafka Streams application.
Resources
Mastering Kafka Streams and ksqlDB: Building real-time data systems by Example by Mitch Seymour
Kafka - The Definitive Guide: Real-Time Data and Stream Processing at Scale by Gwen Shapira, Todd Palino, Rajini Sivaram
View this article on our Medium Publication.

