Introduction
This article is the first in a series of articles on the schema registry and Avro serialization. It provides an overview of Avro and the schema registry, and examines the Avro serialization and deserialization flows in the Kafka consumer and producer.
Messages being written to and consumed from a topic can contain any data as they are byte arrays. By applying a schema it ensures that the message written to a topic by a producer can be read and understood by a consumer of the topic. In order to manage and make such a schema available, a schema registry is used that both the producer and the consumer talk utilise. One such message schema is provided Apache Avro, a serialisation framework which provides type handling and compatibility between versions.
The source code for the accompanying Spring Boot demo application is available here.
See the 'More On Kafka Schema Registry & Avro' below for more articles in this series, including covering the accompanying Spring Boot demo.
The Importance of a Schema
Schemas for Kafka messages are optional, but there are strong benefits for choosing to use them. A schema defines the fields and types of the message ensuring that only those messages that meet this definition will be understandable by the serializer or deserializer. The message schema essentially defines the contract between the event streaming services in the same way that a REST API defines the contract for REST calls. Schemas can evolve and be versioned as message definitions change over time.
Avro Serialization
There are different options around the type of serialization to use for Kafka messages. These include String, JSON, and Protobuf, along with Avro. Each comes with their own advantages and disadvantages, from the performance of serialization, to version compatibility, and the ease of understanding and use. For example the popular JSON serialization provides human readable messages, but lacks typing and version compatibility.
This article focuses on Apache Avro, which is an open source data serialization system. It uses schemas for marshalling and unmarshalling binary data to and from typed records that the Consumer and Producer understand. The schema itself is defined in a JSON format, and the source code representing the message can be generated from this schema.
Schemas can be defined for both message keys and for message values, as the two are serialized and deserialized independently. It is therefore possible to use a standard String Serializer then for the key, and an Avro Serializer for the main message body, for example.
Schema Registry
By sending and consuming messages via Kafka, applications remain decoupled from one another, allowing them to evolve and change without impacting or being impacted by other applications. Utilising a message schema ensures that consumers are able to deserialize messages that have been serialized by another application with the same schema. One option for using a message schema is to include that schema in each message itself, so that the consumer can utilise it to deserialize the payload. However this increases every message size, often doubling it, and that has a direct impact on latency and throughput as more memory and CPU is required by the producer, the broker, and the consumer.
To solve this a schema registry can be used. The schema registry is an independent component that microservices talk to in order to retrieve and apply the required schemas.
The most popular schema registry used for Kafka applications is Confluent’s Schema Registry. This can be run as a standalone service or hosted by Confluent in the cloud. It provides a REST API for administering and retrieving the schemas. New schemas are registered with the Schema Registry, which can happen automatically as part of the serialization flow, via a REST client, or if configured as part of the CI/CD pipeline.
The upshot of using the schema registry as a common repository for the schema is that the microservices that use it remain fully decoupled. The applications are able to evolve independently, with well-defined versioned schemas ensuring the evolving messages can still be understood.
Registering Schemas
Confluent’s Schema Registry uses Kafka itself as its storage backend. The Schema Registry writes the schemas that are being registered to a dedicated, compacted, topic. By default this is called _schemas, although can be configured using the kafkastore.topic Schema Registry parameter.
A new schema or version of an existing schema is registered using the Schema Registry REST API. The REST API can be called manually, or by using the Schema Registry client abstraction provided by Confluent, or triggered via the Confluent Schema Registry maven plugin. Alternatively Confluent’s Kafka Avro serializer can be configured to register the new schema if it does not yet exist. The Schema Registry then consumes the schemas from the _schemas topic, building a copy in a local cache.
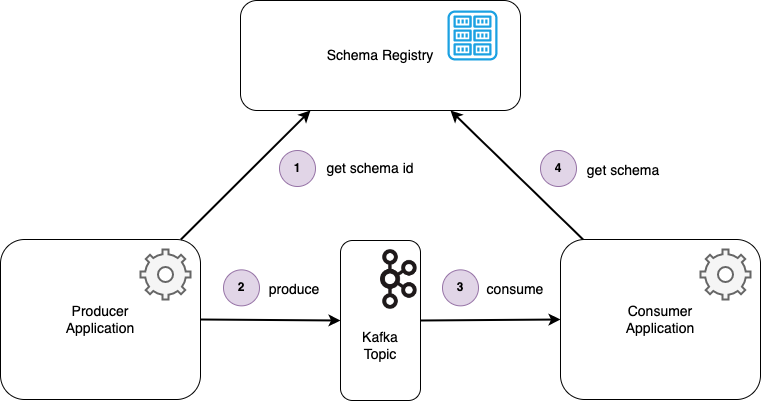
The following diagram illustrates the registration flow:


An Avro schema is registered with the Schema Registry via a REST POST request.

The Schema Registry writes the new schema to the _schemas Kafka topic.

The Schema Registry consumes the new schema from the _schemas topic.

The local cache is updated with the new schema.
When the schema or schema Id is requested from the Schema Registry as happens during the serialization and deserialization flows, the results can be served from the local cache.
By utilizing Kafka as the backend storage for schemas, the Schema Registry therefore gets all the benefits that Kafka provides, such as resiliency and redundancy. For example, if a broker node hosting a _schemas topic partition fails, a replica partition will have a copy of the data.
If the Schema Registry fails and is restarted, or a new instance of the Schema Registry is started, it begins by consuming the schemas available from the compacted _schemas topic to (re)build its local cache.
Serialization & Deserialization
Confluent’s Kafka avro serializer library provides the KafkaAvroSerializer and KafkaAvroDeserializer classes that are responsible for performing the serialization and deserialization of message keys and values. These are registered with the consumer and producer respectively. As part of their de/serialization processing they interact with the Schema Registry as necessary, such that the developer does not need to be concerned with this complexity.
The following diagram illustrates this flow, with a producing application serializing a message, writing it to a Kafka topic, with a downstream application consuming the message and deserializing it.
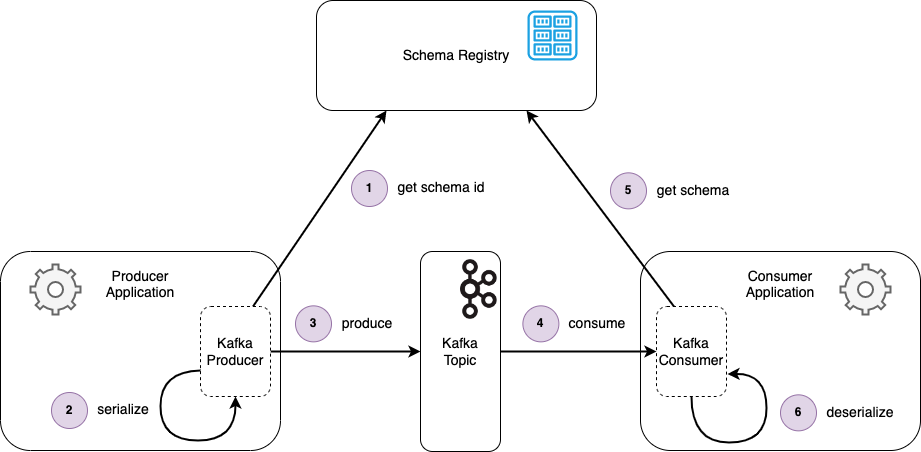
A message is being produced. The Kafka Avro Serializer in the producer gets the schema id associated with the schema of the message (which is obtained by reflection).
The message is serialized in the Avro format, verified using the retrieved schema.
The message is written to the Kafka topic.
The message is consumed from the topic by the Kafka consumer.

The Kafka Avro Deserializer in the consumer gets the schema Id from the message and uses this to look up the schema from the Schema Registry.

The message is deserialized, verified using the retrieved schema.
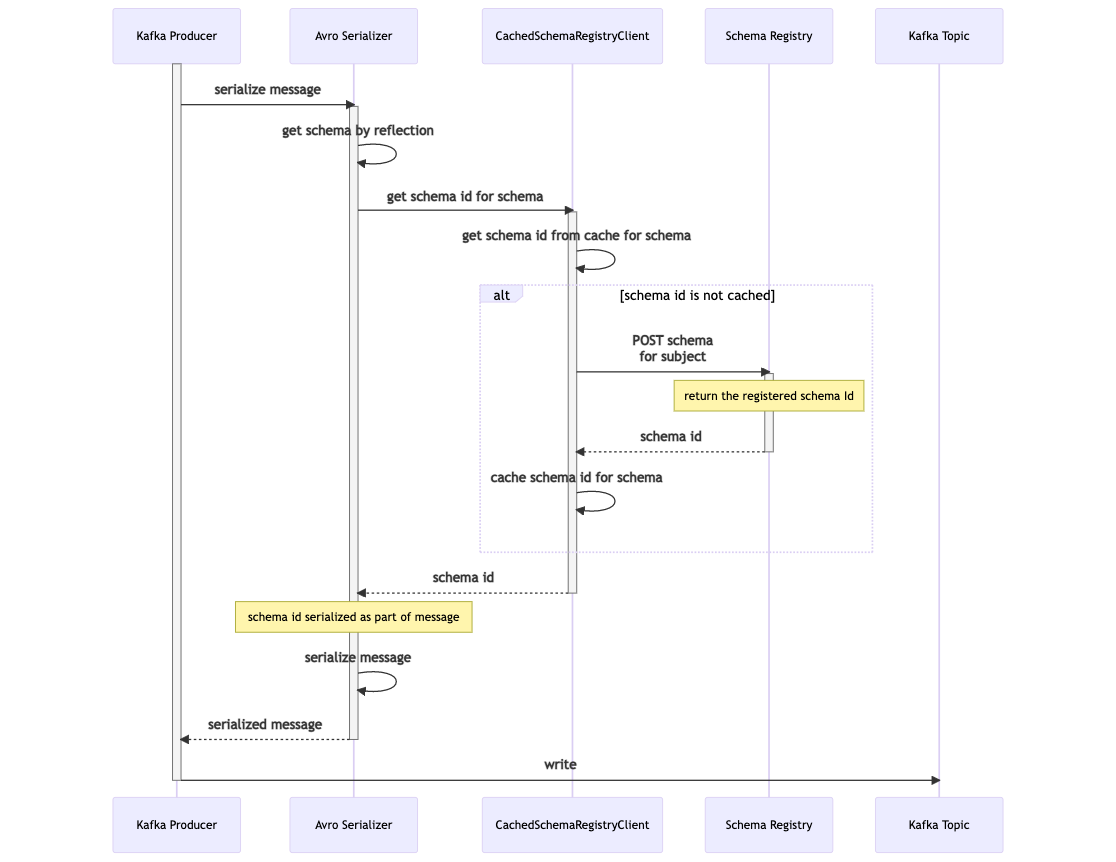
The following sequence diagrams break this flow out into the produce and consume sides. On the produce side, the KafkaAvroSerializer that is assigned to the Kafka producer first obtains the schema from the message class by using reflection. It uses the CachedSchemaRegistryClient, provided by Confluent’s kafka-schema-registry-client library, to obtain the associated schema Id. If the schema Id is not already cached locally then the client calls the Schema Registry via its REST API in order to get this Id. The schema Id is cached locally, ensuring that only on the first occasion is the REST call required for this lookup. At this point the KafkaAvroSerializer serializes the message to a byte array. The serialized message starts with a Confluent serialization format version number (currently always 0) which is known as the ‘magic byte’. This is followed by the schema Id, followed by the rest of the data in Avro’s binary encoding. This is then written to the Kafka topic.
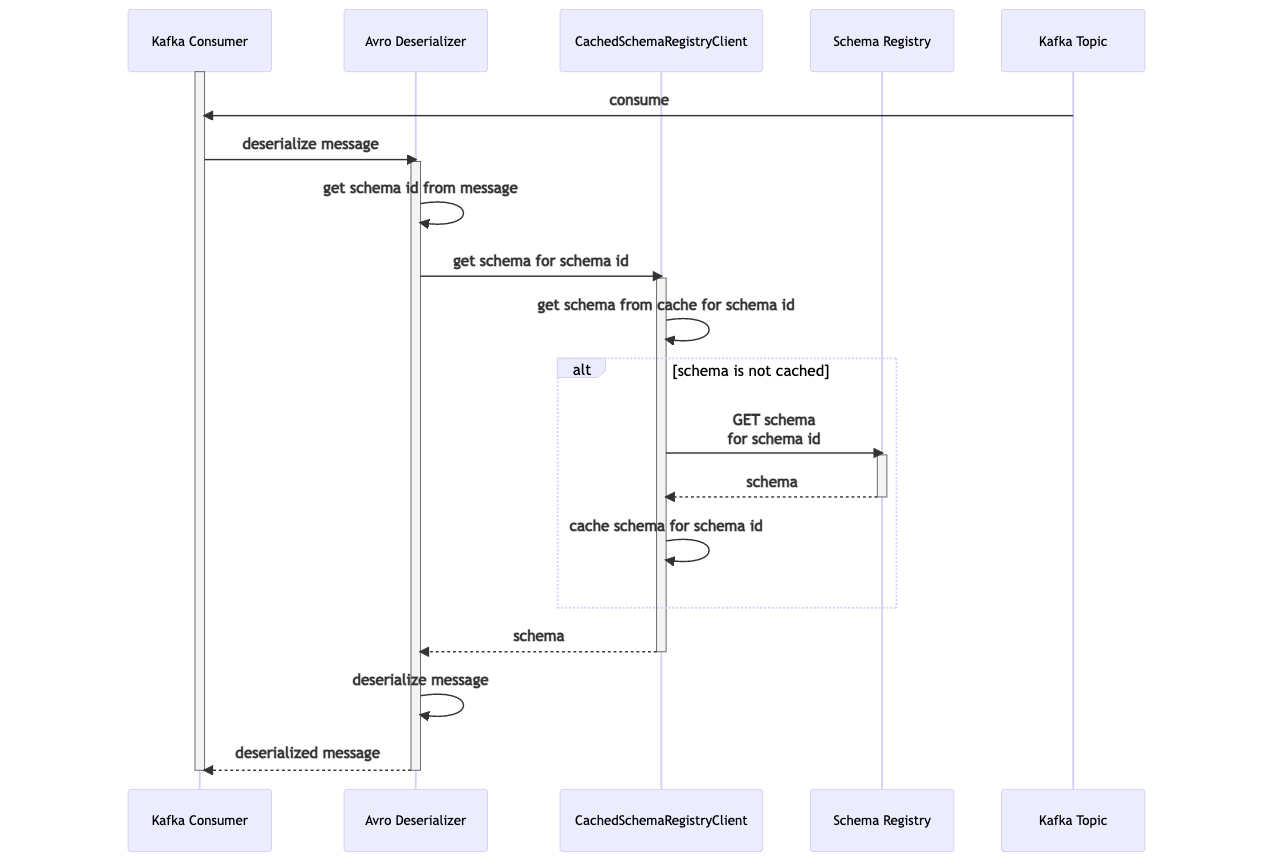
On the consumer side, when a batch of messages is fetched from the Kafka topic and each is handed off to the Kafka consumer, the consumer delegates to the KafkaAvroDeserializer for the deserialization processing. It first extracts the schema Id from the message (stored in bytes 1 to 4), and uses the CachedSchemaRegistryClient which checks the local cache to see if the schema is already present. If not, the client performs a GET schema for the given schema Id. It saves this to its local cache for subsequent messages. It then returns the message back to the KafkaAvroDeserializer which can now deserialize the message to its Avro Class representation using the schema. This is returned to the consumer to continue its processing.
While the developer does not need to write the serialization flows themselves, understanding how it works is of course important, particularly when unexpected errors occur. Beyond that however it is necessary to understand the calls that are made to the Schema Registry when looking to mock these in integration tests. This testing is covered in Kafka Schema Registry & Avro: Integration Testing.
Conclusion
The addition of a schema registry such as Confluent’s Schema Registry into the architecture enables applications to apply schemas to messages sent to and from Kafka. The schema registry stores and manages the schemas allowing the applications themselves to remain decoupled. Schemas essentially define the contract between messaging services. They enable messages to evolve through versioning, enabling the consumer and producer applications to evolve over time. Kafka consumers and producers can use Apache Avro to serialize and deserialize messages, querying and caching the schemas to apply from the schema registry.
Source Code
The source code for the accompanying Spring Boot demo application is available here:
https://github.com/lydtechconsulting/kafka-schema-registry-avro/tree/v1.0.0
[cta-kafka-course]




