Introduction
In the first part of this two part series the reasons to apply message compression and the trade-offs in doing so were considered. In this part the accompanying Spring Boot application is used to demonstrate how to configure compression on the producer, and how to observe the impact of applying the different compression types that are supported.
The source code for the Spring Boot application is here.
Spring Boot Demo Overview
The accompanying Spring Boot application is designed to demonstrate message compression. The application exposes a REST endpoint that allows a caller to request a configurable number of events to be produced. The application is configured to send each message asynchronously, and has a linger.ms of a few milliseconds configured. This enables the producer to batch up the messages which results in more effective compression. As the compressed batches are written to Kafka the consumer then receives these batches as it polls. It decompresses each batch so the messages are ready for processing.
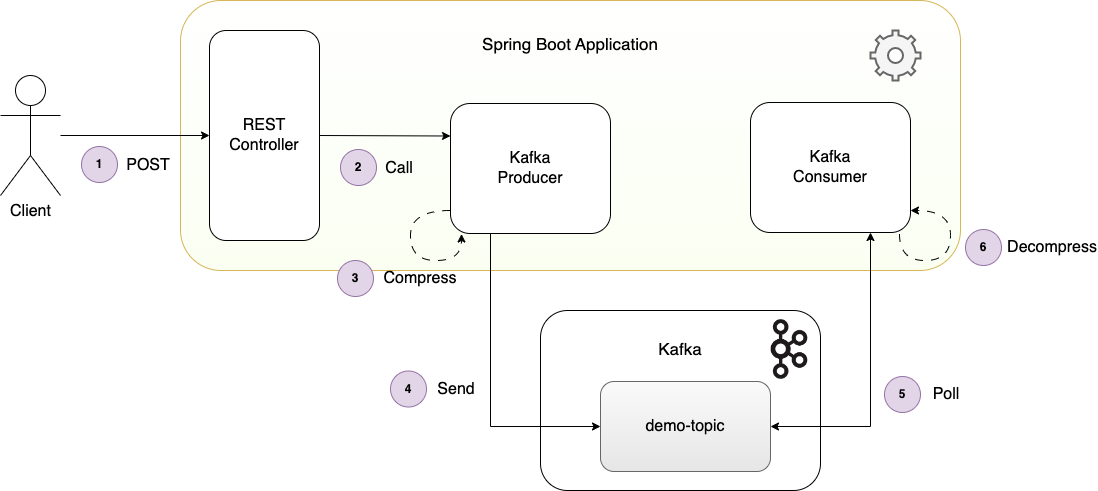

The client sends a REST POST request to the application to trigger sending a number of events.

The REST Controller calls the Kafka producer to send the events.

The producer compresses each batch of messages using the configured compression codec.

The producer sends each compressed batch of messages to the topic where it is written to disk.

The Kafka consumer polls the topic and receives each batch of messages.

The consumer decompresses each batch of messages.
Configuration
The producer configuration is declared in the application.yml.
kafka:
producer:
compressionType: gzip
lingerMs: 10
async: true
The properties lingerMs and compressionType are set on the ProducerFactory Spring bean that is used by the KafkaTemplate to send the events. This is configured in the KafkaDemoConfiguration configuration class.
config.put(ProducerConfig.LINGER_MS_CONFIG, lingerMs);
config.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, compressionType);
Producer
The events are constructed in the DemoService, which delegates to the KafkaProducer to send using the KafkaTemplate:
final ProducerRecord record = new ProducerRecord<>(properties.getOutboundTopic(), key, payload);
final Future result = kafkaTemplate.send(record);
The call to send each message returns a Future, so if the result is not waited on before the next message is sent then the producer is able to batch these events. The async property in the application.yml determines whether to send asynchronously or not, and this is acted upon in the DemoService.
The events themselves have around 15 fields covering names, address and contact details, and the values are randomised Strings. The repetition of the field names in particular between the messages within a batch make these good candidates for compression.
Consumer
When the Kafka consumer polls the topic for the message batches, the batches are decompressed when received. Spring Kafka hands each uncompressed message to the application handler KafkaDemoConsumer, so there is no explicit code required to be implemented by the developer for the decompression.
Demo Execution
In order to run the application against a local instance of Kafka, docker-compose is used to start up Kafka and Zookeeper in docker containers, using the following command executed from the root of the project:
docker-compose.yml up -d
Optionally Conduktor Platform can also be started, which provides a UI over the broker, topics and messages, providing an option to see the impact of the compression. To also start Conduktor, use the following command in place of the one above:
docker-compose-conduktor.yml up -d
The Spring Boot application is built using maven, and the application is started:
mvn clean install
java -jar target/kafka-message-compression-1.0.0.jar
The REST request to the application can be sent using curl, and this specifies the number of events for the application to send. The Spring Boot application is running on port 9001:
curl -v -d '{"numberOfEvents":10000}' -H "Content-Type: application/json" -X POST http://localhost:9001/v1/demo/trigger
The request should be accepted immediately with a 202 ACCEPTED response, as the application hands off processing the request to send events asynchronously.
Observing Compression Effect
The effect of the compression can be observed via two methods. First of all, Kafka provides a command line tool that can be used to query the size of the topic that the messages have been written to. Jump on to the Kafka docker container, and run the kafka-log-dirs command as follows:
docker exec -it kafka /bin/sh
usr/bin/kafka-log-dirs \
--bootstrap-server 127.0.0.1:9092 \
--topic-list demo-topic \
--describe \
| grep -oP '(?<=size":)\d+' \
| awk '{ sum += $1 } END { print sum }'
The output is the size of the topic in bytes.
The second option is to log in to Conduktor, assuming this has been started as described above. Navigate in the browser to:
http://localhost:8080
Login with the default credentials admin@conduktor.io / admin, and navigate to the Console to view the topics. Select the demo-topic to observe its size:

Override Producer Configuration
It is straightforward to override the producer configuration in the application.yml that is described above. For the changes to take affect the application must be rebuilt and restarted. Alternatively, a second application.yml file is provided in the root of the project. This can be edited to change relevant configurations such as the compressionType, lingerMs, and async. With these configurations updated, run the Spring Boot application with the following command in place of the one described above:
java -jar target/kafka-message-compression-1.0.0.jar -Dspring.config.additional-location=file:./application.yml
Compression Comparison Results
Two test runs were undertaken to first highlight the difference in effectiveness of the compression types, and second the impact of sending large batches against single message batches.
Large Batch
To maximize batch size, the producer send mode must be asynchronous. This means that the call to send for each message does not wait for the acknowledgement from the broker. This enables the Kafka producer to build up a batch of messages which it sends in a single request. The producer linger.ms is set to 10 milliseconds, which is the duration the producer waits while it builds up the message batch. This of course adds to latency.
- Mode: async
- Producer linger.ms: 10
- Number of events sent: 10000
Compression TypeTopic Size (bytes)none5271108gzip2340481snappy3323984lz43385693zstd2200524
Small Batch
To ensure each batch contains only a single message, the producer send mode is set to synchronous. The producer is not able to build up a batch of messages as the application will await the acknowledgement of the send from the broker for each individual message before it processes the next message. The producer linger.ms is therefore set to 0 milliseconds to avoid any additional latency.
- Mode: sync
- Producer linger.ms: 0
- Number of events sent: 10000
Results
With the data set used in this test, the compression types zstd and gzip proved to provide the most effective compression. It is also clear that for each compression type large batches of messages are compressed far more effectively than small batches (in this case, single message batches). This is expected as the amount of repeated data across the large message batches will allow for better compression.
Note this demonstration only compares the effectiveness of the compression type. The results will vary depending on the type of data used. It also does not show the other factors that must be considered when selecting a compression type including CPU usage and compression speed. These factors are compared and contrasted in the first article.
Conclusion
Spring Boot and Spring Kafka make it incredibly simple to apply compression to message batches sent by the producer. On the consumer side there are no changes required to the application, as the message batches consumed are transparently decompressed before the messages are passed through to the application handlers. The application demonstrated how the different compression types had a varying effectiveness on the amount of compression applied. There was also a significant difference evident on the effectiveness of the compression based on whether the message batches were large or small. Larger batches mean there is more repeated data that enables greater compression.
Source Code
The source code for the accompanying Spring Boot demo application is available here:
https://github.com/lydtechconsulting/kafka-message-compression/tree/v1.0.0
[cta-kafka-course]




