Introduction
Producers are able to compress batches of messages that are sent to the Kafka broker, which can then store them on disk in compressed format. This article looks at the advantages that this can bring to the system, and also the trade-offs that should be considered when adopting message compression. It is also important to understand what the influences on the amount of compression that can be achieved are, from the supported compression codecs to the amount of message batching by the producer.
In the second article, message compression is demonstrated using a Spring Boot application. The source code for the companion application is here.
Why Compress?
Compressing a batch of messages means that the producer request sent over the network contains this compressed batch, this is then stored on the Kafka broker, and the consumer receives the compressed batch over the network when it polls for messages.
There are therefore two main advantages to compressing messages that are sent to the Kafka broker:
- Reduced network bandwidth
- Less broker disk space usage where the messages are written.
Network bottlenecks can impact throughput, so reducing the size of the requests by compression reduces this impact. Likewise there can be disk space constraints or costs to storing data that are mitigated by writing data in a compressed format.
There are trade-offs with choosing to compress messages that are sent to Kafka:
- Higher CPU utilization
- Increased latency
This extra CPU usage is required to compress the messages on the producer, and to decompress on the consumer. In some configurations compression and decompression is also required on the broker. However this increased CPU usage is slight, and if this is a concern then this would be a main consideration when selecting the compression codec to use.
In order for compression to be most effective it works best on larger batches. Therefore to achieve optimum compression it is common to add a slight delay in the send to allow the batch to build up (see below for more on this). This adds latency to the send.
Compression Codecs
Spring Kafka 3 offers four compression codecs on the producer and topic that each have different characteristics. It will therefore be down to the use cases to determine which compression codec should be selected.
Broker, Topic & Producer Compression
There are three places where compression can be configured and two places that compression can be applied, and it is important to understand how they affect one another.
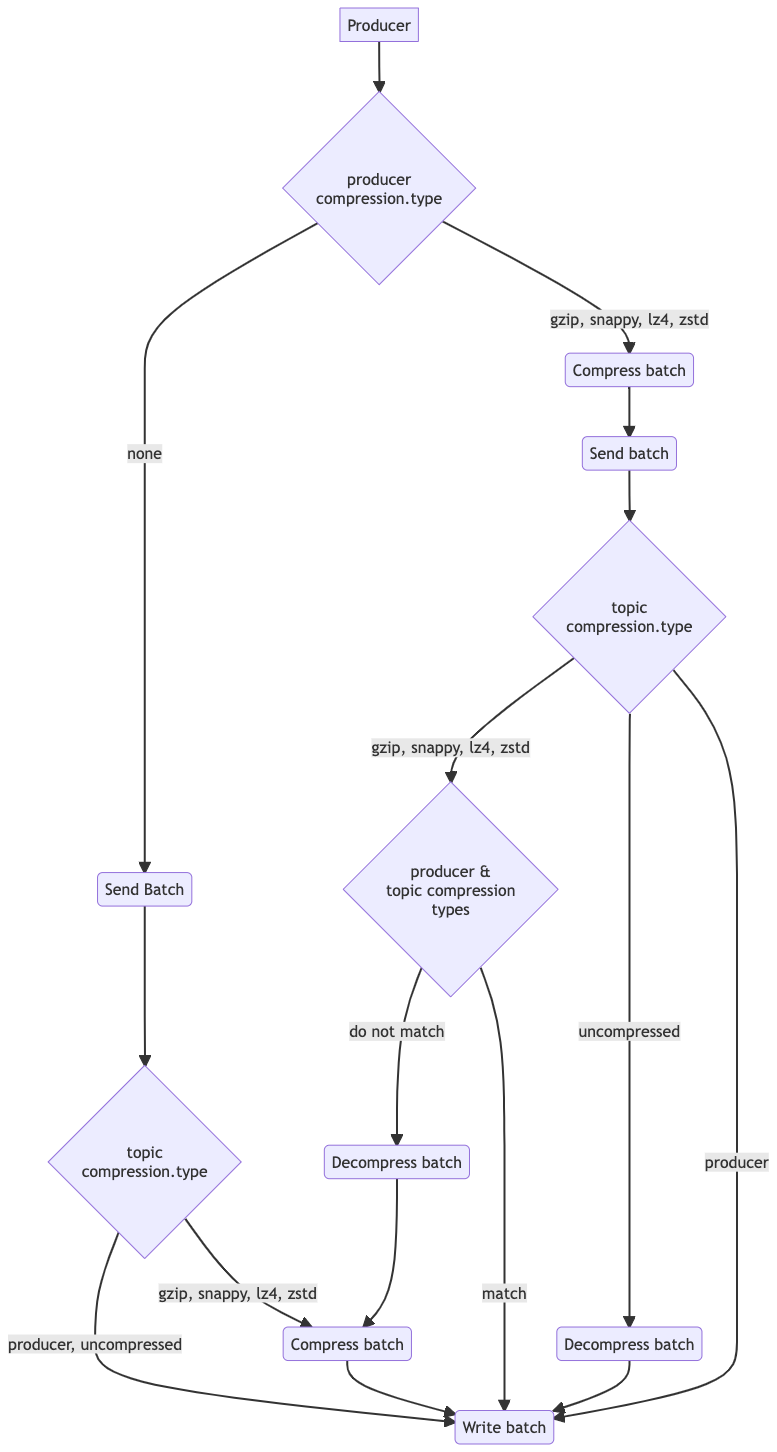
By default if no configuration changes are made, there is no compression applied either by the producer nor the broker. This is because compression is set to none on the producer, and the broker and topics are configured to use the compression set on the producer.
When a topic is created it will apply the compression.type configured on the broker, unless it is overridden for the topic. If a compression type is configured on the producer, then the batch of messages (one or more) is compressed with that format and sent to the topic on the broker. With the default value for the topic, then the message batch is written to disk in its compressed format, and is decompressed transparently by the consumer.
If the topic’s compression type is not producer, and does not match the producer’s compression type then the message batch will be decompressed. Then, if the topic compression type is uncompressed, the message batch will be written to disk uncompressed. Otherwise it is recompressed to the specified topic compression type before being written. In this latter case, again the message batch is decompressed transparently by the consumer upon receipt.
The following flow diagram shows what compression will occur based on the interplay of the topic and producer compression.type configurations - remembering that the topic will inherit the broker compression.type if not overridden:
Message Batching
Compression works on a batch of messages, and it is most effective the more messages in a batch. This is because the compression algorithms typically look for repeated character sequences which can be compressed in size. For example, messages in the same format such as JSON and XML have the same field names, and these will compress well.
It is therefore prudent to consider how to achieve optimal batching if attempting to get the full benefits of batching. Sending a message at a time, waiting for the send to complete successfully before attempting the send of the next message, results in a batch of one. In this case compression will be less effective, and indeed a produce request will be sent on the network for each single message batch which is sub-optimal.
In order to increase the occurrence of larger batches, the linger.ms configuration parameter can be used on the producer. By configuring this to a few milliseconds, then the producer waits for this period to accumulate more messages that it can include in the batch. Remember each batch will contain messages for one partition, so the usage of message keys that may route messages to different partitions could have a bearing on the batch size.
Adding a short delay for this does have the trade-off of adding latency to each message, as the producer waits to fill the batch. So this needs to be carefully considered and tuned for the application. The linger.ms parameter is covered in more detail in the article Kafka Producer Message Batching.
Consumer Decompression
The consumer will transparently decompress a batch of messages that it receives. Once again the overhead here is the slight CPU increase required to perform the decompression.
Kafka Pre-0.10 Behaviour
In versions of Kafka prior to 0.10 the processing of compressed batches on the broker was different. In those versions every compressed batch received on the broker had to be decompressed, the messages validated and offsets assigned, before being recompressed. This requirement is no longer the case as producers now set the relative offsets before the batch is sent, meaning the broker no longer needs to recompress the batch (assuming no difference in compression type between producer and broker).
Encryption
By their nature, encrypted messages will not have repetitive character sequences, and so compression of encrypted messages is ineffective. There are also security exploits documented on compressed encrypted messages that are sent over an insecure network. It is therefore generally recommended to disable compression if message encryption is enabled.
Conclusion
By compressing batches of messages when they are produced and/or on the broker means that network bandwidth and disk storage space are both reduced. There are a number of compression codecs that can be selected, themselves with different trade-offs to consider, from the effectiveness of the compression to the time to compress. The trade-off for compressing messages is a slight increase in CPU utilization, as well as a likely increase in latency.
Source Code
The source code for the accompanying Spring Boot demo application is available here:
https://github.com/lydtechconsulting/kafka-message-compression/tree/v1.0.0
More On Kafka Message Compression
Kafka Message Compression (2 of 2): Spring Boot Demo: The accompanying application is covered, demonstrating configuring the producer to compress messages and observing the differences when different compression types are applied.
[cta-kafka-course]




