Introduction
Kafka is a distributed messaging system that provides resiliency, high availability, and fault tolerance. One of the means it uses to achieve this is data replication across broker nodes. If a broker node fails then replicated data in a topic partition is not lost, and it can still be consumed from replica partitions. The level of redundancy is configurable, but the cost of redundancy is an increase in latency as the data is replicated. Understanding this configuration, from producer acks, to replication factor and minimum in-sync replicas, is therefore essential.
Minimum In-sync Replicas
When a Kafka producer writes a message to a topic, it writes it to the partition replica leader. This is a replica that has been voted the leader by the broker from its list of in-sync replicas that are distributed across a cluster of broker nodes. The data written to the leader by the producer is then replicated across the partition replica followers. This is controlled by the topic's replication factor. A value of 3 means that the data is replicated from the leader to two follower partitions, ensuring a total of three replicas hold the data.
While the data is replicated across the follower partitions, the min.insync.replicas configuration parameter controls the minimum number of these replicas (including the leader) that must successfully write the data to their log file when the producer is configured with acks equal to all. While there is a minimum number of in-sync replicas configured, all replicas that are in-sync at the time of the write must acknowledge the write before it is considered successful.
ISR
The partition replica leader tracks the set of replicas that are in-sync, in the set known as the ISR (In-Sync Replicas). Partition replica followers send fetch requests to the leader to get the latest log entries. Each partition replica leader tracks the lag of its follower replicas. If the leader does not receive a fetch request within the configured replica.lag.time.max.ms, or the follower has not consumed up to the leader’s log end within this period, then the follower is considered out of sync and is removed from the ISR.
A partition replica is also considered out of sync if it loses connectivity with Zookeeper. This timeout is configurable via zookeeper.session.timeout.ms.
Under Replicated Partition
When the required number of replicas exist for a topic partition, but one or more of the replicas have fallen behind the partition leader by a significant amount, this is considered an under replicated partition. This is an important metric to monitor, as a healthy cluster would expect to have no under replicated partitions.
High Watermark Offset
The high watermark offset is the latest offset that has been written to all the in-sync topic partition replicas. The records up to this high watermark offset are considered committed and durable. While producers only ever write to the leader replica, consumers can read events from the leader or any follower too. However they are only able to read up to this highwater mark offset. Follower partition replicas are informed of the latest highwater mark offset by the leader replica. Once synchronous replication has been acknowledged by all the follower replicas in the ISR, then the leader replica informs its followers of the new highwater mark. This metadata is passed to the follower replicas in the response to their fetch requests.
Replication Configuration
There are a number of configuration parameters that play a part in Kafka’s replication protocol and that are covered in this article. The main ones of interest are listed here.
ParameterConfig TypeUsageDefault ValueacksProducerThe number of acks the producer requires from the broker for a successful writealldefault.replication.factorBrokerThe replication factor for auto created topics1min.insync.replicasBroker & TopicThe minimum number of replicas allowed in an ISR set which must all acknowledge a write when producer acks is all. Uses the broker value unless configured on the topic.1replica.lag.time.max.msBrokerThe max lag time a replica can lag before being removed from the ISR30 seconds
When a topic is auto-created it is configured with the default.replication.factor. If it is created using the Kafka Admin tools, then the --replication-factor parameter can be used to specify the required replication for the specific topic.
Replication Example
To illustrate the replication behaviour, an example cluster of three broker nodes, with a single topic, itself with a single partition is used. The following configuration is in place:
ConfigValueacksalldefault.replication.factor3min.insync.replicas2
The starting point is that the topic partition has two records written (foo and bar). The default.replication.factor is set to 3, and these records have been replicated across to broker nodes 2 and 3. Each replica therefore has a log end offset of 2, and a highwater mark offset of 2.
A third message is now written (xyz) by the Kafka producer to the partition replica leader, at offset 3. This has been replicated to the follower on node 2 and acknowledged back to the leader successfully, but has not yet been replicated to node 3.

If the partition follower replica on node 3 is not considered in-sync, then all the replicas that are in the ISR (the leader on node 1, and the follower on node 2) have written the record to their respective log file. The write is considered successful, and the leader acknowledges the write to the producer.
If the partition follower replica on node 3 is considered in-sync (and therefore in the ISR), then although the min.insync.replicas of 2 has been met, not all in-sync replicas have acknowledged the write. Only once the follower on node 3 acknowledges the write is the leader able to acknowledge the write to the producer. This highlights the potential of extra latency as the replication factor is increased, as the write is only as fast as the slowest in-sync replica.
Producer Acks
When the producer acks is not set to all then the min.insync.replicas setting is not of consequence. If in the above example the producer acks is set to 1 then only the partition replica leader, i.e. the replica that the producer writes to, must acknowledge the write. Once it has, although the record is considered successfully written, with a replication factor of 3the write is still replicated to the two follower partition replicas. However the risk is that before the write is replicated the leader could fail, resulting in data loss as the producer believes the write was successful.
When the producer acks is set to 0 the produce is a fire and forget, as the producer does not await for any acknowledgement from the partition replica leader. Whether the write has succeeded or not the producer has completed its processing.
Producer acks configuration is covered in detail in the article Kafka Producer Acks.
Producer Retry
If a producer write fails because a node fails resulting in there being insufficient replicas to satisfy the min in-sync replicas number, a transient exception denoting there not being enough replicas available is thrown. This would happen in the case in the above example where min.insync.replicas is 3, but node 3 fails, meaning the second follower replica fails before it has acknowledged the replicated write. If the producer is configured to retry on a transient error (which it is by default) it will do so in this scenario. This would allow a new replica to be promoted to the in-sync replicas list, the write to be successfully replicated on retry, and hence the write to succeed.
Note that configuring the producer retries parameters can result in duplicate messages being written to the topic. For more on this, see the article Kafka Idempotent Producer.
Replication Flow
The following diagrams illustrate the replication flow. The first diagram shows the simpler scenario with an ISR containing the partition replica leader, and one partition replica follower. min.insync.replicas is 2 and producer acks is all, so both replicas must acknowledge the write. The starting point is that both have the highwater mark offset of 2. A new record is written to the leader.

The follower partition fetches the latest records from the leader with the same mechanism that a consumer fetches records from a partition. The fetch informs the leader of the follower’s current offset. It is able to use this to determine if the follower is lagging, and which records it needs to catch up. The fetch response contains any new records, as well as the latest highwater mark. In this case it is the new record at offset 3. The highwater mark offset is 2. The follower writes the record and performs another fetch. The leader now sees the replica has caught up to offset 3. As in this two in-sync replica scenario all replicas in the ISR are caught up, the leader updates its highwater offset mark to 3, and returns this in the fetch response to the follower. The leader is able to acknowledge the write to the producer, marking that as complete. Meanwhile the follower is able to update its own highwater mark offset.
In the next diagram the complexity increases as a second follower is added. All three replicas are in the ISR so must acknowledge the write before it is considered successful with the producer.
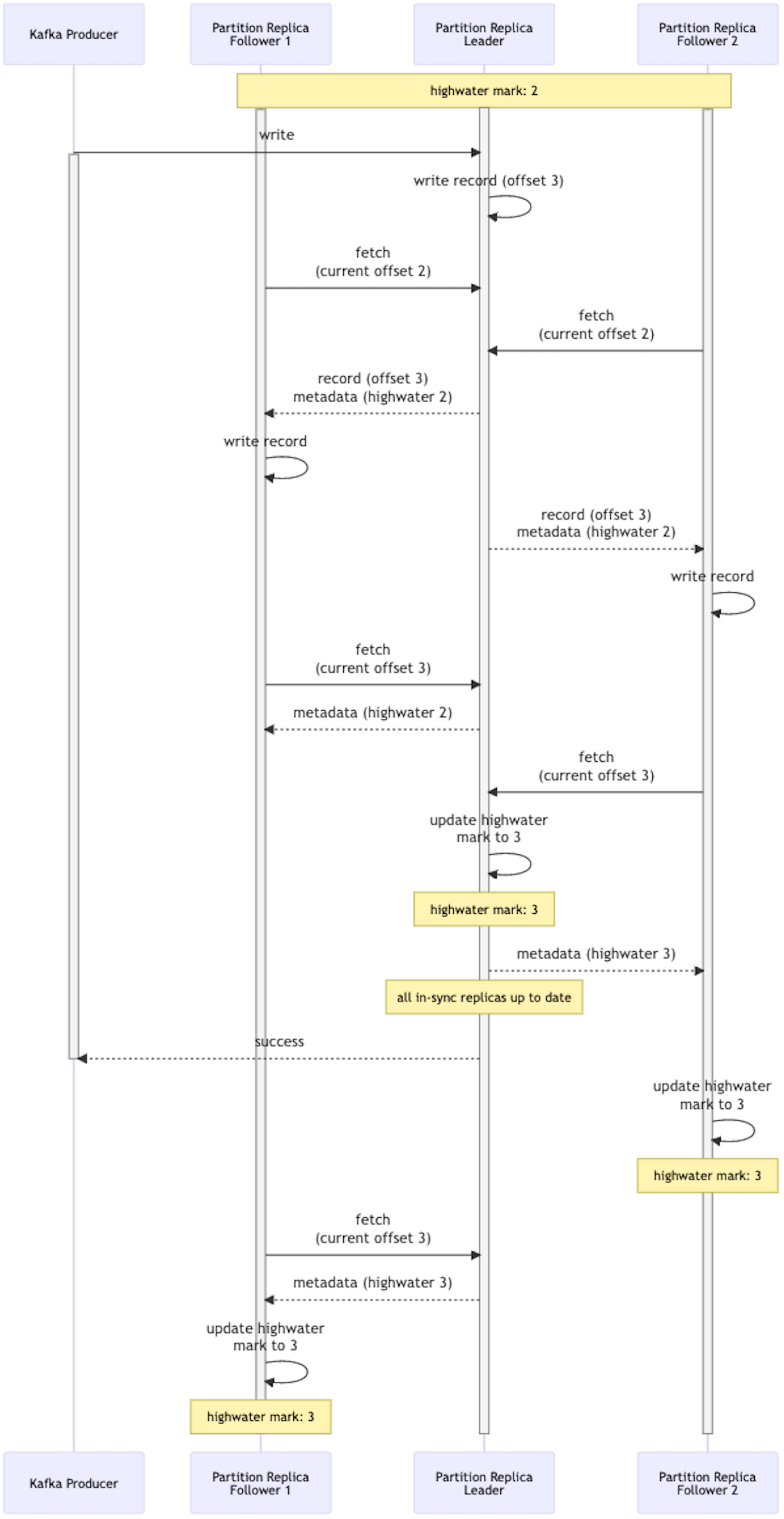
Only once the leader has received acknowledgement from both followers (which it gets through each follower fetch request) is it able to update the highwater mark offset. At this point it is able to acknowledge the write with the producer, and let each follower know the new highwater mark offset in their fetch request responses. This illustrates the latency added for consumers that are reading data from follower partitions. The consumers are only allowed to read data up to this highwater mark offset, so until that is updated the records are not available to consume. This then is a trade-off between availability, spreading of the work across nodes, and latency.
Durability & Availability vs Latency
By increasing the number of required minimum in-sync replicas the durability of the data is increased, as data is guaranteed to be replicated across more nodes at a point of failure. It also results in high availability, as even if a broker node fails consumers are still able to read data from replica partitions. The trade-off is the increase in latency, as each extra replica in the in-sync replica set (ISR) must acknowledge the write to the replica partition leader for the write to succeed. This impact is greater when the nodes in the cluster span data centres or availability zones.
Unclean Leader Election
If a broker node fails, the leader partitions that it hosted need to be reassigned across the remaining nodes in the cluster. With unclean leader election disabled, it is ensured that only a partition that was in-sync with the leader before the leader died will be elected. If unclean leader election is enabled, then an out of sync replica can become leader if no in-sync replicas are available. This results in data loss, as the messages that had not been replicated to this replica are lost. This therefore is a trade-off between data consistency and high availability. This is covered in detail in Kafka Unclean Leader Election.
Replication for Internal Topics
Consumer Offsets
Kafka consumers use an internal topic, __consumer_offsets, to mark a message as successfully consumed. This topic uses the broker min.insyc.replicas configuration to determine whether a consumer offset write has satisfied this requirement. It uses the offsets.topic.replication.factor to determine how many replica copies are made. The parameter offsets.commit.required.acks plays the same role as the Kafka producer acks property. By default it is -1 (i.e. all), meaning the write must be replicated to the ISR, and satisfy the min.insync.replicas setting, before it is considered successful.
The additional configuration parameters are:
ParameterConfig TypeUsageDefault Valueoffsets.topic.replication.factorBrokerThe replication factor for the offsets log3offsets.commit.required.acksBrokerThe number of acks required for an offset commit to be successful-1 (all)
Transaction State Log
The transaction state log is used to track and manage Kafka transactions. This is an internal topic called __transaction_state. Its minimum in-sync replica requirement is based on the transaction.state.log.min.isr broker configuration. It uses the transaction.state.log.replication.factor configuration to determine how many replica copies are made.
The additional configuration parameters are:
ParameterConfig TypeUsageDefault Valuetransaction.state.log.replication.factorBrokerThe replication factor for the transaction topic3transaction.state.log.min.isrBrokerThe min ISR for the transaction topic2
Conclusion
Data replication and the minimum in-sync replicas configuration are key elements to Kafka’s resiliency and redundancy guarantees. There are a number of parameters across the broker, topics, and producers that interplay and must be carefully configured to achieve the required behaviour. The configurer has the decision to trade-off ensuring a higher level of durability of data in failure scenarios and higher availability for consumers, against the resulting increase in latency as the data is replicated across broker nodes.
[cta-kafka-course]




