Introduction
When an event consumed from Kafka needs to be retried, the retry can either be blocking or non-blocking. Blocking retry means that subsequent events on the partition will not be processed until the retrying event has completed successfully or otherwise. Non-blocking retry means that those later events can be consumed and processed while the original event is being retried. The trade-off for achieving non-blocking retry is that the order of events being processed can no longer be guaranteed.
This is the second of a two part series on non-blocking retry. In the first part non-blocking retry using Spring Kafka was detailed. Spring Kafka provides excellent support with minimal coding required to implement a non-blocking retry pattern. However, for applications not written using Spring, or indeed not using Apache Kafka, then this article describes the design for a generic non-blocking retry pattern that could be applied.
The source code for the accompanying Spring Boot demo application is available here.
For a general overview on consumer retry, and for use cases that require blocking retry, see the article Kafka Consumer Retry.
Non-Blocking Retry Pattern
This article covers the same use case as covered in the first article, whereby an update-item event is received before the item has been persisted to the database via a create-item event. The intention is that the update-item event should be retried for a configurable period to allow time for the create-item event to be received and processed, at which point the update can be successfully applied.
To achieve non-blocking retry, an additional retry topic is created, and if the update-item event cannot be processed (as the database lookup fails to find the item in this scenario), it is written to this retry topic. At this point the update-item is marked as successfully consumed from the original topic, and the next events can be processed.
A consumer for the retry topic consumes the retrying events, and performs the following steps:
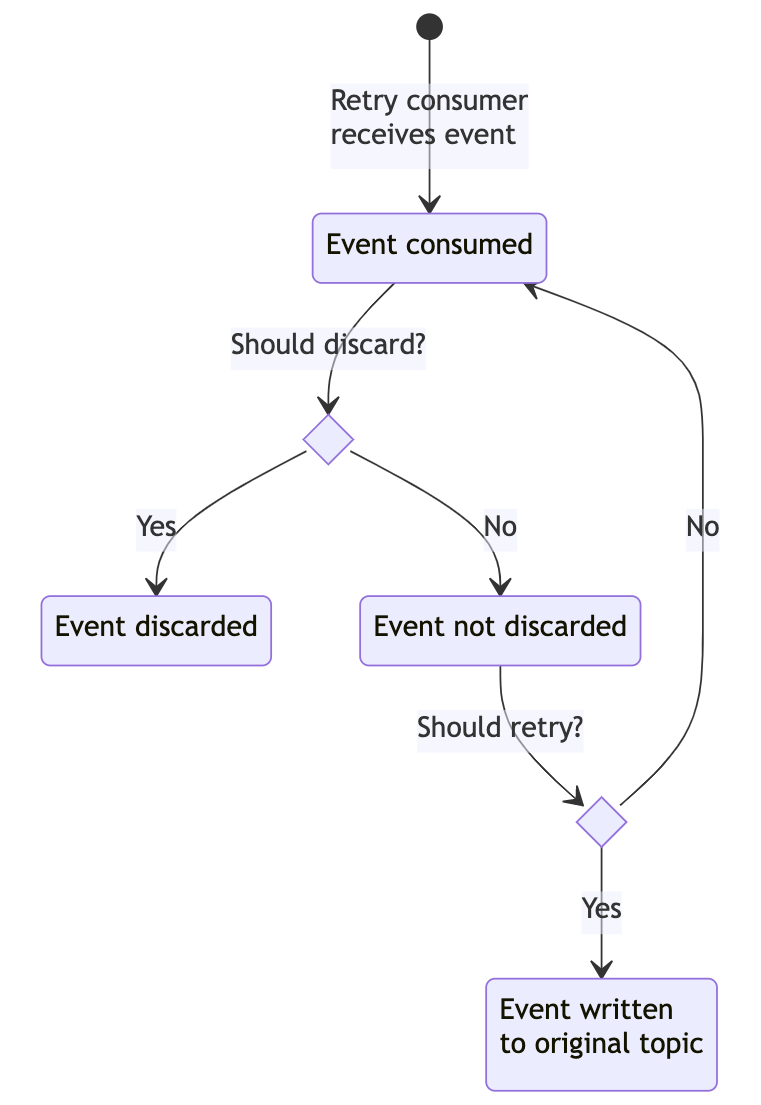
- Check if the item should be discarded: discard if the difference between now and the original event receipt date is greater than the max retry duration.
- If not discarded, check if the item should be retried: retry if the difference between now and the retry received date is greater than the retry interval.
- If the item should be retried, then write it back to the original topic. If not then re-poll the event from the retry topic.
The following sequence diagram shows the full flow with the update-item event being received by the Kafka consumer, then determining whether the event should be retried via the retry topic, and then the retry flow itself.

The key aspects here are that once the event is eligible to be retried (as the retry interval has been exceeded), then it is placed back on the original topic and so follows the same original processing flow, which might once again result in a retry. If the event is not ready for retry, it is simply re-polled from the retry topic until it should either be discarded, or is ready for retry.
The retry logic in the RetryService has no knowledge of what processing is required when the event is ready to be retried. Once the retry criteria has been met it simply writes the event back to the original topic. The original event consumer will once again consume and process this message, which will again either result in it being processed successfully or written back to the retry topic if it requires a further retry.
This pattern requires tracking the timestamp of when the event was first received on the original topic. This is required in order to calculate if the event should be discarded as the maximum retry duration has been exceeded. The original received timestamp is therefore tracked and added each time the event is written back to the original topic and onto the retry topic. The original topic name is also added as a header, so that the RetryService knows which topic to write the event back to when it has satisfied the retry criteria.
Spring Boot Demo
The accompanying Spring Boot project demonstrates this non-blocking retry pattern. It covers the use case where an update-item event is received before its corresponding create-item event, so the item is not available in the database to be updated. The update-item is therefore retried until the item has been created.


The update-item event is consumed by the update item consumer from the update-item topic.

The attempt to update the item on the database fails as the item does not exist.

The update-item event is written to the retry topic.

The update-item event is consumed by the retry consumer.

The event is checked as to whether it should be discarded, retried, or re-polled from this retry topic. In this scenario it is determined to be retried, and is written to the update-item topic.

The create-item event is now consumed by the create item consumer from the create-item topic.

The item is persisted in the database.

The update-item event is again consumed by the update item consumer from the update-item topic.

The attempt to update the item on the database succeeds as the item now exists.
The update-item is consumed by the UpdateItemConsumer from the update-item topic and passes the event to the ItemService to process. The service looks up the item on the database, and if it is not found it delegates to the RetryService to handle the retry processing. The RetryService writes the event to the ACTIVE topic, along with the original received timestamp as a header.
public void retry(final String payload, final MessageHeaders headers) {
final Long verifiedOriginalReceivedTimestamp = headers.get(MessagingRetryHeaders.ORIGINAL_RECEIVED_TIMESTAMP) != null ?
(Long)headers.get(MessagingRetryHeaders.ORIGINAL_RECEIVED_TIMESTAMP) : (Long)headers.get(RECEIVED_TIMESTAMP);
kafkaClient.sendMessage(retryTopic, payload,
Map.of(MessagingRetryHeaders.ORIGINAL_RECEIVED_TIMESTAMP, verifiedOriginalReceivedTimestamp,
MessagingRetryHeaders.ORIGINAL_RECEIVED_TOPIC, headers.get(RECEIVED_TOPIC)));
}
The update-item event is then consumed from the messaging-retry topic by the RetryConsumer. The consumer passes the event to the RetryService, which determines whether the update-item event should be discarded, retried via the original item-update topic, or re-polled from the messaging-retry topic as neither of the previous conditions have been satisfied.
public void handle(final String payload, final Long receivedTimestamp, final Long originalReceivedTimestamp, final String originalTopic) {
if(shouldDiscard(originalReceivedTimestamp)) {
log.debug("Item {} has exceeded total retry duration - item discarded.", payload);
} else if(shouldRetry(receivedTimestamp)) {
log.debug("Item {} is ready to retry - sending to update-item topic.", payload);
kafkaClient.sendMessage(originalTopic, payload,
Map.of(MessagingRetryHeaders.ORIGINAL_RECEIVED_TIMESTAMP, originalReceivedTimestamp));
} else {
log.debug("Item {} is not yet ready to retry on the update-item topic - delaying.", payload);
throw new RetryableMessagingException("Delaying attempt to retry item "+payload);
}
}
The retry topic name, retry interval, and maximum retry duration are all configurable via the application.yml.
retry:
messaging:
topic: "messaging-retry"
retryIntervalSeconds: 10
maxRetryDurationSeconds: 300
The RetryService, RetryConsumer and associated classes are encapsulated in a separate module, messaging-retry. This is a reusable library that could be extracted from this demo and utilised wherever this pattern is required. The demo application therefore includes this as a dependency in its pom.xml:
<dependency>
<groupId>demo</groupId>
<artifactId>messaging-retry</artifactId>
<version>1.0.0</version>
</dependency>
Running The Demo
Note that the demo steps are the same as those for the demo described in the Kafka Consumer Non-Blocking Retry: Spring Retry Topics article, as the two patterns result in the same retry behaviour:
To run the demo docker is used to bring up a dockerised Kafka and Zookeeper for the application to integrate with, in the provided docker-compose.yml. The Conduktor Platform is also started in docker. Conduktor is a web application that provides a UI over the broker and topic. The application is built and run as an executable jar file.
docker-compose up -d
mvn clean install
java -jar demo-service/target/kafka-retry-with-delay-1.0.0.jar
The Kafka command line tools are used to produce the necessary events to the broker, from which the application will consume. First the update-item event is written, which attempts to update the associated item’s status to ACTIVE. This event can be observed being written to each of the retry topics while the application is unable to find the item in the database.
kafka-console-producer \
--topic update-item \
--broker-list kafka:29092
{"id": "626bd1bd-c565-48ac-87b2-28f2247f6dea", "status": "ACTIVE"}
The application provides a REST endpoint (in ItemController) that can be hit to retrieve the item status. curl can be used to check the status of the item. As the item is not found at this point, a 404 NOT FOUND is returned:
curl -X GET http://localhost:9001/v1/demo/items/626bd1bd-c565-48ac-87b2-28f2247f6dea/status
Next the create-item event is written to Kafka:
kafka-console-producer \
--topic create-item \
--broker-list kafka:29092
{"id": "626bd1bd-c565-48ac-87b2-28f2247f6dea", "name": "my-new-item"}
The event is consumed by the application, and the item is created in the database with status PENDING. If the update-item is still being retried then the status update will be applied. Using curl the status of the item will now be returned.
The steps for running the demo are also covered in the project Readme.
Integration Testing
Spring Boot integration tests are used to verify the retry behaviour with an in-memory embedded Kafka broker. The embedded broker is provided by the Spring-Kafka library, so if not using Spring as might be the case if adopting this pattern over Spring retry topics, then an alternative testing approach must be utilised. To that end the flow could be tested using a dockerised Kafka, and Lydtech’s open source component-test-framework will enable this kind of testing. The article Kafka Consume & Produce: Testing goes into detail on setting up and running component tests with Kafka as the messaging broker.
To provide a direct comparison with the Spring Retryable topics pattern for non-blocking retry, the integration test KafkaIntegrationTest is using the embedded broker to prove the retry behaviour. It tests the three scenarios:
- The create events are received before the corresponding update events, so no retry required.
- The update events are received before the corresponding create events, so must be retried before completing successfully.
- An update event is received and retried but the corresponding create event is never received, so the update event is eventually discarded.
Conclusion
The non-blocking retry pattern described in this article provides a generic approach to retrying events. The demo project provides a reusable library that can be utilised by any Java application looking to apply this pattern. Alternatively this small library could be re-written in the language of choice for use with non-Java based applications. If the application is Spring based, then using the Spring-Kafka retry topics as described in the first article would be the recommended approach. That provides the simplest and most configurable solution with the least coding required to achieve non-blocking retry.
As with the Spring Kafka retry topics, the trade-off with this non-blocking retry pattern is that the order that events are processed in can no longer be guaranteed. A later event may complete processing while an earlier event is being retried.
Source Code
The source code for the accompanying Spring Boot demo application is available here:
https://github.com/lydtechconsulting/kafka-retry-with-delay/tree/v1.0.0
[cta-kafka-course]




