Introduction
A relational database would be the natural choice for hosting a message deduplication table. However if the application uses a NoSQL database then adding an additional resource in the shape of a relational database solely for the purposes of deduplication might be considered unwarranted.
This blog post follows on from the Idempotent Consumer & Transactional Outbox patterns article which delved into using Postgres as the backend database for deduplication. This article explores using the same Idempotent Consumer pattern but swapping in DynamoDB as the backing store in place of Postgres. It compares and contrasts the two in the context of a Spring Boot application, looking at Spring’s support for DynamoDB, the different transactional behaviour, and its ramifications for deduplication in different failure scenarios.
The article also covers options for testing the behaviour, using SpringBoot tests with in-memory Kafka and DynamoDB, and component tests using TestContainers to spin up dockerised Kafka and LocalDynamoDB, that latter facilitated by AWS LocalStack.
Source code accompanying this article is available at: https://github.com/lydtechconsulting/kafka-idempotent-consumer-dynamodb
DynamoDB and Spring
Spring does not offer first class support for DynamoDB. There is no official Pivotal supported DynamoDB module available. Therefore the developer will be writing the boiler plate code when integrating with DynamoDB, and using the amazon DynamoDB SDK. Spring JPA is not compatible with DynamoDB. While with a relational database a service method can be annotated @Transactional to wrap the processing calls declared in the method to be within a transaction, this feature is not available with DynamoDB.
A further limitation with the Amazon DynamoDB SDK is that it is not possible to do the three steps: begin transaction, process, commit transaction. Instead all DynamoDB writes that must occur within a single transaction must occur within the single transactWriteItems() call, following any processing. This contrasts with the Spring JPA’s @Transactional annotation that allows us to wrap any number of calls within a transactional context.
Deduplication
The lack of fine grained control of DynamoBD transactions has important ramifications for deduplication. First let us understand how deduplication is implemented with the Idempotent Consumer pattern. A table is introduced ‘processed_events’, with a single column ‘id’. When an event is consumed the event Id associated with the message is written to this table. The event Id might be in the message payload, or sent as a Kafka message header. If a message is received with the same event Id, this write to the processed_messages table would result in a conflict, and the message is rejected as a duplicate.
Failure Scenario Leading to Duplicates
The failure scenario where duplicate messages can arise and be processed simultaneously is when a consumer exceeds the consumer timeout while processing a message. If the consumer does not complete the processing before the max consumer poll timeout is exceeded, the Kafka broker believes the consumer instance may have died. It therefore removes the consumer instance from the consumer group and performs a consumer group rebalance. A new consumer instance is assigned to the topic partition, which polls the partition and receives the same message:
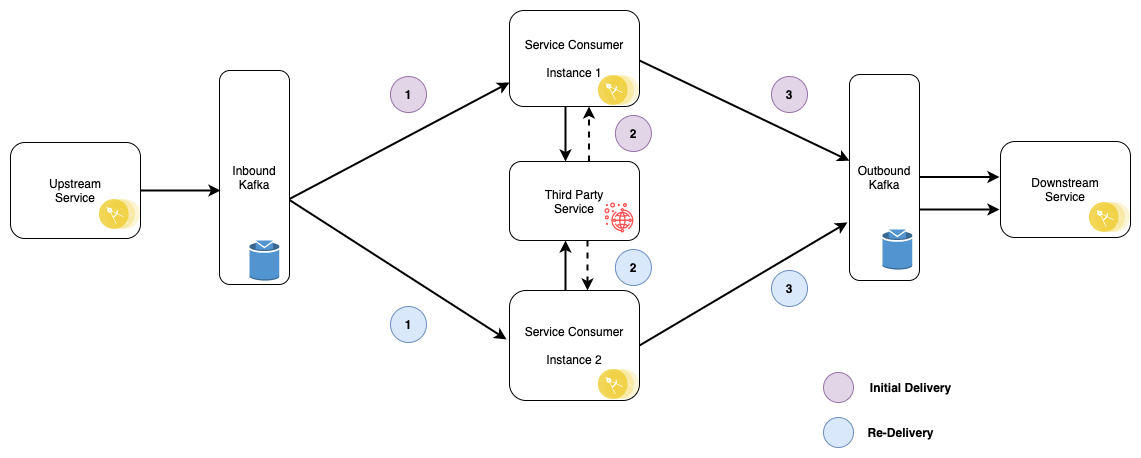

The message sent to the broker by the upstream service is consumed by instance 1

The consumer poll times out as the 3PP service takes too long to respond.
The consumer instance 1 is removed from the consumer group as the broker thinks it has died. The consumer group rebalances and the consumer instance 2 is assigned to the topic partition.

The message (duplicate) is consumed by instance 2

The message is processed simultaneously by instance 2 as it has not been deduplicated.

Instance 1 emits an outbound event and writes the eventId to the processed_events table.

Instance 2 emits an outbound event before the deduplication write is attempted and fails.
Assuming the first message is still being processed, but the eventId has not yet been written before the second consumer instance eventId query is undertaken, both messages will be processed. Any resulting REST calls or outbound event publishing for example will likewise be duplicated, potentially leaving the system in an inconsistent state.
Deduplicate with a Relational Database
Taking a typical implementation with a relational database such as Postgres and using Spring JPA, the following code demonstrates what is required for our deduplication write:
private void deduplicate(UUID eventId) throws DuplicateEventException {
try {
processedEventRepository.saveAndFlush(new ProcessedEvent(eventId));
} catch (DataIntegrityViolationException e) {
log.info("Event already processed: {}", eventId);
throw new DuplicateEventException(eventId);
}
}
The transaction is started by the Spring framework aspect as the thread is about to enter the method. The write using saveAndFlush() essentially locks the row with that primary key, the PK being the eventId. If a second thread attempts to perform the same saveAndFlush() call with the same eventId, the thread must wait to acquire the transaction lock on this record. Meanwhile the first thread continues, processing the message. Once the thread exits the annotated method Spring JPA will either commit or rollback the transaction. If the transaction commits successfully then the lock request by the second thread is rejected and an exception is thrown back. If the first transaction fails and is rolled back, then the second thread is now able to acquire the lock, and its processing is able to continue.
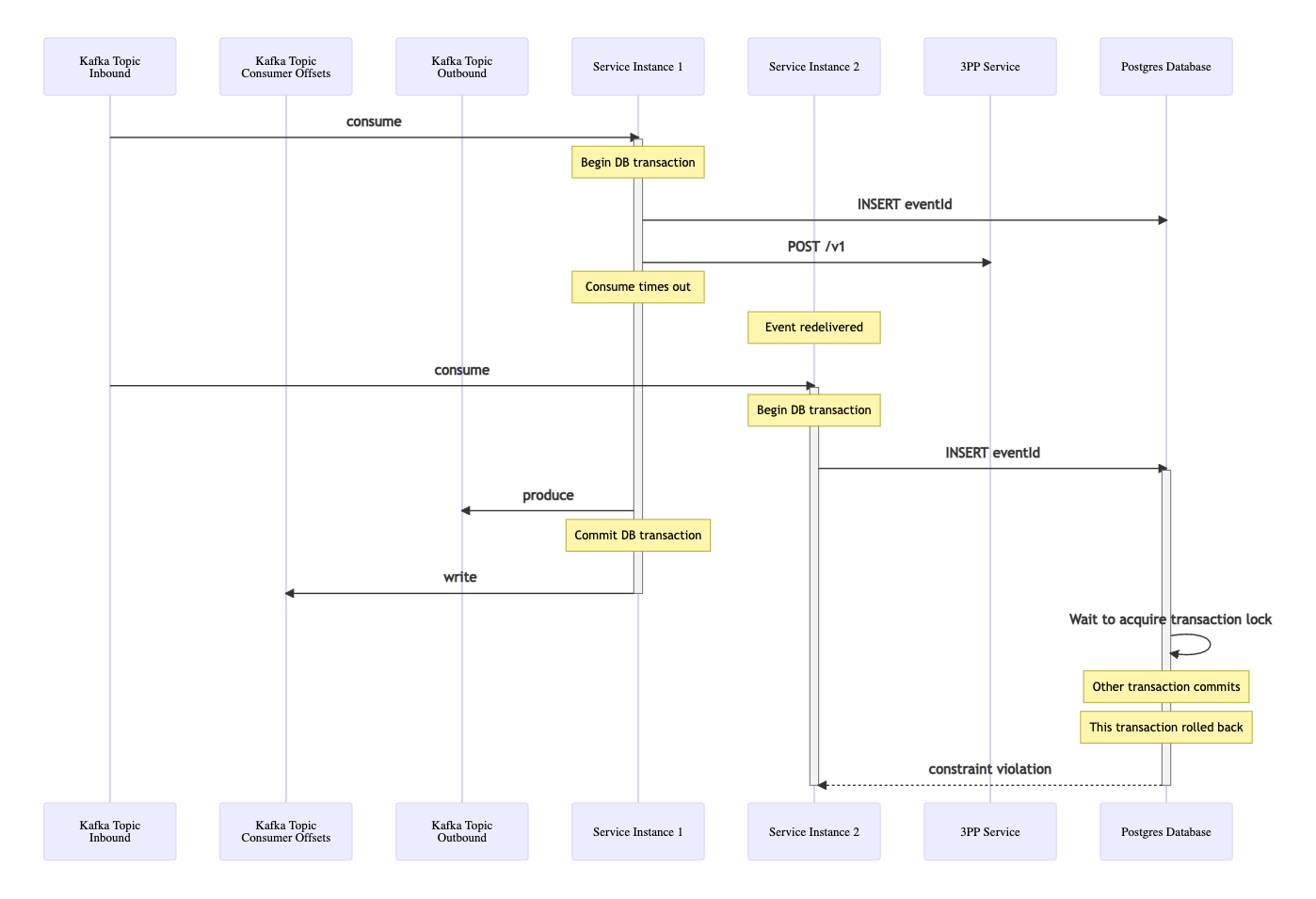
This deduplication with Postgres as the backing store is covered in detail in the Idempotent Consumer & Transactional Outbox patterns article.
Deduplicate with DynamoDB
With the Amazon DynamoDB SDK, the transaction write is implemented using the server-side transactions API. However this API does not allow the three step: begin transaction, process, commit transaction. Instead there is a single call to perform the eventId write. If the service was also undertaking other DynamoDB entity writes then the transaction write would ensure this was atomic. In this example there are no other entities being created or updated, so using the non-transactional save() call suffices. This write must occur after the rest of the message processing has completed. If the eventId write happened first, and the service then failed, when the message is redelivered it would immediately be deduplicated as the eventId was already committed to the processed_messages table. Therefore the write must be the last action that takes place before the consumer offsets write occurs, which essentially marks the message as consumed (which is taken care of by Spring Kafka).
The upshot of this then is that an additional query is required before the message processing occurs, to check if the eventId has already been written to the database. If it has, the message is rejected as a duplicate, if it has not then the message is processed. The deduplication code using DynamoDB then looks like this:
public void process(String eventId, String key, DemoInboundEvent event) {
try {
// 1. Check if the event is a duplicate.
Map eav = new HashMap();
eav.put(":v1", new AttributeValue().withS(eventId));
DynamoDBQueryExpression queryExpression = new DynamoDBQueryExpression()
.withKeyConditionExpression("Id = :v1")
.withExpressionAttributeValues(eav);
List duplicateEventIds = dynamoDBMapper.query(ProcessedEvent.class, queryExpression);
if(duplicateEventIds.size()>0) {
log.info("Duplicate event received: " + eventId);
throw new DuplicateEventException(eventId);
}
// 2. Perform the event processing.
callThirdparty(key);
kafkaClient.sendMessage(key, event.getData());
// 3. Record the processed event Id to allow duplicates to be detected.
ProcessedEvent processedEvent = new ProcessedEvent(eventId);
DynamoDBSaveExpression saveExpression = new DynamoDBSaveExpression()
.withExpectedEntry("Id", new ExpectedAttributeValue().withExists(false));
dynamoDBMapper.save(processedEvent, saveExpression);
} catch (ConditionalCheckFailedException e) {
log.info("ConditionalCheckFailedException Error: " + e.getMessage());
throw new DuplicateEventException(eventId);
} catch (DuplicateEventException e) {
throw e;
} catch (Exception e) {
log.error("Exception thrown: " + e.getMessage(), e);
throw e;
}
}
There is clearly a lot more complexity here when compared to the Spring JPA code using a relational database. The expectation would be that this code would be placed in a reusable library that any application required to deduplicate messages would pull in to use. So the code would not be being written by a developer in each application, and there would be one suite of comprehensive tests for this logic, going someway to mitigating the downside of the extra complexity.
DynamoBD Deduplication Limitation
Code complexity to one side, there is a more significant problem with the DynamoDB deduplication approach. There is a window where two (or more) threads could both have performed the eventId query but neither has just committed the eventId, so neither is rejected as a duplicate. Both would process their duplicate message, hence resulting in duplicate REST calls and duplicate outbound event writes, and any other business logic that takes place. The first thread would complete and commit the eventId, the second thread commit would be rejected, but the duplicate processing would already have occurred. If the database write encompassed updating other entities within a transaction then these would however be rolled back.
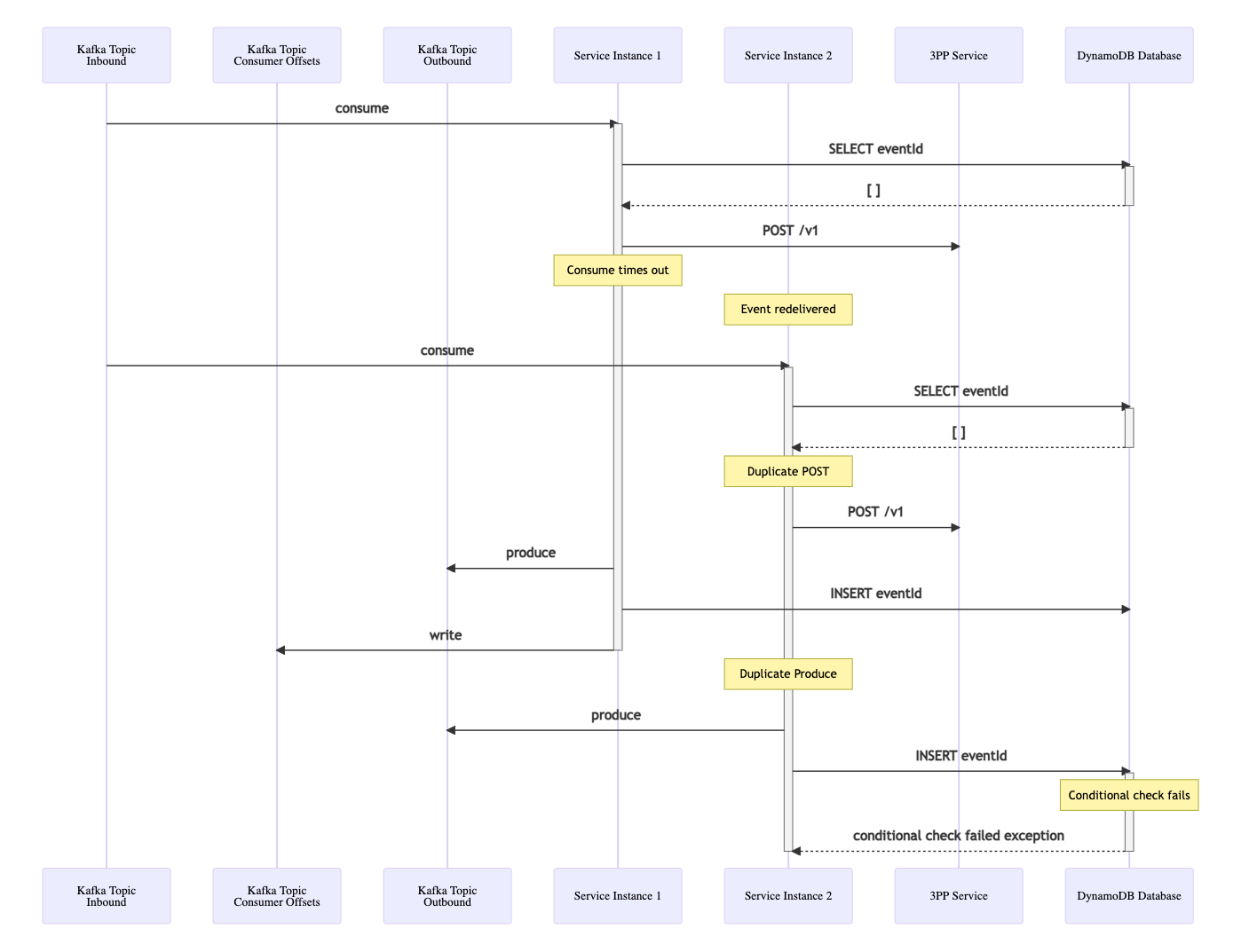
In the relational database example, this problem is avoided due to the record lock that is acquired on the eventId before the message processing occurs via the overarching transaction.
Using a Message Key
In many failure scenarios where a duplicate message is being consumed this does not present a problem using DynamoDB as the backing store when the Kafka messages have a key. All messages written to a Kafka topic with the same key go to the same partition. This will be the case for duplicate messages, as by definition they will have the same key. Consider a non-idempotent Producer in the upstream service that writes multiple duplicates to the topic partition. As these messages are processed serially from any one partition by one consumer this means that the eventId write will have completed before the duplicate message is processed. It will therefore be successfully rejected as a duplicate. The problem in the cited example where the consumer group rebalances is that there are then two different consumers that are processing the duplicates, so they can be processed in parallel.
Mitigation Options
There are options to mitigate this consumer group rebalance scenario where messages are not correctly deduplicated. One option is to reduce the window to as small a time period as possible for critical deduplications by performing a secondary eventId query right before any final resulting event is published for example, to check if a duplicate has completed processing in the meantime. However the secondary query adds complexity, is harder to test, and is not guaranteed to stop the duplicate processing.
Alternatively a lock mechanism could be implemented with an expiry timestamp that is written before the message is processed. When a message is received then the deduplication check will check for the presence of a lock and will not process until either the duplicate has completed processing or the lock has expired.
Another possibility is to accept these duplicates. REST calls could be designed to be deduplicated by the target service, if that is a possibility. The outbound events could be deduplicated downstream, if that is within the control of the system. Although note that these duplicate outbound events will have unique eventIds, so the idempotent consumer pattern would not cater for deduplicating these events.
It would also be possible to explore using a lower level DynamoDB transaction API, to use the finer grained begin transaction, process message, commit transaction flow as with Spring JPA. A couple of libraries may be able to be used here are the following:
awslabs amazon-dynamodb-lock-client library to utilise a locking strategy.
https://github.com/awslabs/amazon-dynamodb-lock-client
As a labs project there would be concern using this in a Production environment. It does not look to be maintained, nor up to date with the latest AWS Java SDK.
awslabs dynamodb-transactions library to start transaction, process event, commit transaction.
https://github.com/awslabs/dynamodb-transactions
Another labs project. Again this does not looked to be maintained, and the repository ReadMe states from November 2018 to use the official DynamoDB server-side transactions (although this does not offer the fine grained control that is required).
Testing
Spring Boot Tests
The accompanying Git repository contains Spring Boot tests that test the deduplication behaviour. Spring Boot tests offer the ability to test using an in-memory embedded Kafka Broker and in-memory Local DynamoDB instance. This enables developers to get quick feedback against these in-memory resources that offer similar functionality to their real counterparts. This shifts tests left: for most coding errors they would be uncovered here, rather than having to wait until the code is deployed to run against the real resources at the component test stage. However it must be noted that the Local DynamoDB is using SQLite behind the scenes, so can only really be used to verify DynamoDB API calls are correct rather than for testing more advanced scenarios.
The following test demonstrates event deduplication when multiple duplicates are published to the topic partition (perhaps by a non-idempotent producer) where they share the same Kafka message key:
/**
* Send in three events and show two are deduplicated by the idempotent consumer, as only one outbound event is emitted.
*/
@Test
public void testEventDeduplication() throws Exception {
String key = UUID.randomUUID().toString();
String eventId = UUID.randomUUID().toString();
stubWiremock("/api/kafkawithdynamodbdemo/" + key, 200, "Success");
DemoInboundEvent inboundEvent = buildDemoInboundEvent(key);
sendMessage(DEMO_INBOUND_TEST_TOPIC, eventId, key, inboundEvent);
sendMessage(DEMO_INBOUND_TEST_TOPIC, eventId, key, inboundEvent);
sendMessage(DEMO_INBOUND_TEST_TOPIC, eventId, key, inboundEvent);
// Check for a message being emitted on demo-outbound-topic
Awaitility.await().atMost(10, TimeUnit.SECONDS).pollDelay(100, TimeUnit.MILLISECONDS)
.until(testReceiver.counter::get, equalTo(1));
// Now check the duplicate event has been deduplicated.
TimeUnit.SECONDS.sleep(5);
assertThat(testReceiver.counter.get(), equalTo(1));
verify(exactly(1), getRequestedFor(urlEqualTo("/api/kafkawithdynamodbdemo/" + key)));
}
The annotations and class rule on the Spring Boot tests enable the in-memory resources:
@ExtendWith(LocalDbCreationRule.class)
@EmbeddedKafka(controlledShutdown = true, topics = { "demo-inbound-topic" })
public class IdempotentConsumerIntegrationTest extends IntegrationTestBase {
@ClassRule
public static LocalDbCreationRule dynamoDB = new LocalDbCreationRule();
View the full source code here: IdempotentConsumerIntegrationTest
Component Tests
The component tests in the accompanying Git repository utilise TestContainers, a Java library providing a framework for running and managing resources in docker containers. They spin up a dockerised Kafka broker, a dockerised Localstack container running DynamoDB as the database, and a dockerised wiremock to represent a third party service. This call to the third party service simulates a delayed response, enabling messages sent in parallel to be processed in the same time window. The Localstack DynamoDB again is an approximation of the real DynamoDB, so different behaviour could be encountered compared to testing against a real DynamoDB instance. Two instances of the service are also started in docker containers. View the ReadMe file for steps to run the test.
The deduplication behaviour using DynamoDB as the backing store in the scenario where multiple duplicate messages are written to the same topic partition is demonstrated in the component test IdempotentConsumerCT. As the messages have been produced with the same message header key they are consumed by the same consumer instance, serially processed, and so deduplicated successfully.
A consumer group rebalance is forced in the component test ConsumerRebalanceCT. This is achieved by utilising wiremock behaviour mappings to add a delay to the response to the call to the 3PP service. The consumer poll times out so the message is redelivered to the second consumer group. This illustrates the scenario described above where deduplication is not successful with DynamoDB, with the upshot being two resulting events emitted.
Conclusion
DynamoDB can be used as the backing store for deduplicating events using the Idempotent Consumer pattern, however its limitations in comparison to the relational database must be understood.
Spring Boot integration tests offer good support for testing with the in-memory LocalDynamoDB (albeit backed by SQLite), and the Kafka embedded broker.
Component tests using TestContainers allows testing behaviour against a Localstack DynamoDB, again not a real DynamoDB instance, and a real Kafka instance. Other services can be wiremocked and dockerised, and multiple instances of the service can be spun up providing as close an approximation to a real deployment for a developer to test against.
Source Code
The source code accompanying this article is available here: https://github.com/lydtechconsulting/kafka-idempotent-consumer-dynamodb




